
일반적인 데이터베이스 개론에서 트랜잭션 개념과 회복 다음 내용이므로 순서대로 공부하는 것을 선호하신다면 데이터베이스 트랜잭션 개념과 회복까지 학습하시면 도움이 될 수 있습니다. 잘못된 부분이 있다면 피드백 부탁드립니다.
들어가기 앞서

이 글을 읽기 전에 이전에 다룬 견고하게 트랜잭션 스케줄(Transaction Schedules) 개념 잡기 를 먼저 읽는 다면 도움이 될 것이다. 일반적으로는 트랜잭션의 병행 수행에 의한 문제를 다루고, 스케줄링을 공부한 이후 병행 제어를 배운다.
하지만 반대로 나는 문제가 생기지 않는 병행 수행을 이해하기 위한 스케줄링에 대한 개념을 먼저 다루었다. 비직렬 스케줄에 따라 여러 트랜잭션을 인터리빙 방식으로 병행 수행한다면 갱신 분실, 모순성, 연쇄 복귀 등의 문제가 일어날 수 있다고 언급했었다. 이번 글에서는 그 부분에 대해서 다뤄 보도록 하겠다.
병행 수행과 병행 제어
데이터베이스 관리 시스템은 여러 사용자가 데이터베이스를 동시에 공유할 수 있도록 여러 트랜잭션이 동시에 수행되는 병행 수행(concurrency)을 지원한다. 병행 수행은 여러 트랜잭션들이 차례로 번갈아 수행되는 인터리빙 방식으로 진행된다. 또한 트랜잭션의 순서를 고려하지 않으면 데이터베이스의 일관성을 보증할 수 없다.(즉, 무결성을 보장하기 어려움) 따라서 병행 제어(concurrency control)가 필요하며 이것은 동시성 제어라고도 한다. 즉, 병행 수행 시 같은 데이터에 접근하여 연산을 실행해도 문제가 발생하지 않고 정확한 수행 결과를 얻을 수 있도록 트랜잭션의 수행을 제어하는 것을 의미한다. 다시 말하자면 병행 제어는 결국 직렬 가능한 스케줄을 만들기 위함이라 생각할 수 있다.
병행 수행의 문제
병행 수행을 특별한 제어 없이 한다면 여러 문제가 발생할 수 있다. 대표적인 문제로는 갱신 분실, 모순성, 연쇄 복귀가 있다. 가볍게 한번 알아보자.
갱신 분실(lost update)
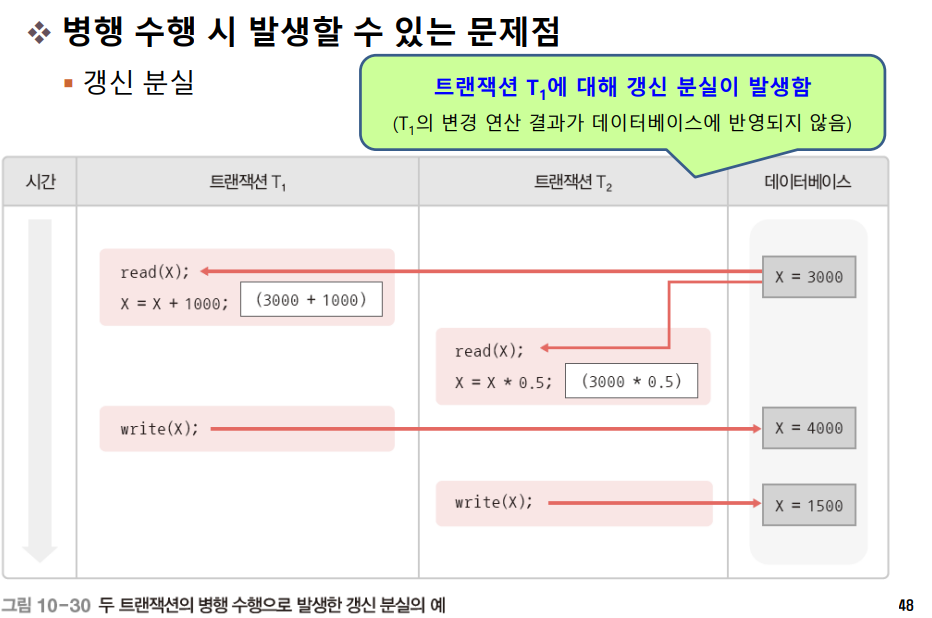
하나의 트랜잭션이 수행한 데이터 변경 연산의 결과를 다른 트랜잭션이 덮어써서 변경 연산이 무효화되는 것이다. 예를 들어 데이터 X에 1000을 더하는 트랜잭션 T₁과 데이터 X를 50% 감소시키는 트랜잭션 T₂ 가 병행 수행될 때, 아래처럼 T₁ 의 write(X) 연산이 무효화된 것을 알 수 있다. 갱신 분실을 예방하기 위해선 여러 트랜잭션이 동시에 수행되더라도 마치 트랜잭션들을 순차적으로 수행한 것과 같은 결과 값을 얻을 수 있어야 한다.(즉, 직렬 가능한 스케줄이어야 갱신 분실이 발생하지 않는다.)
모순성(inconsistency)
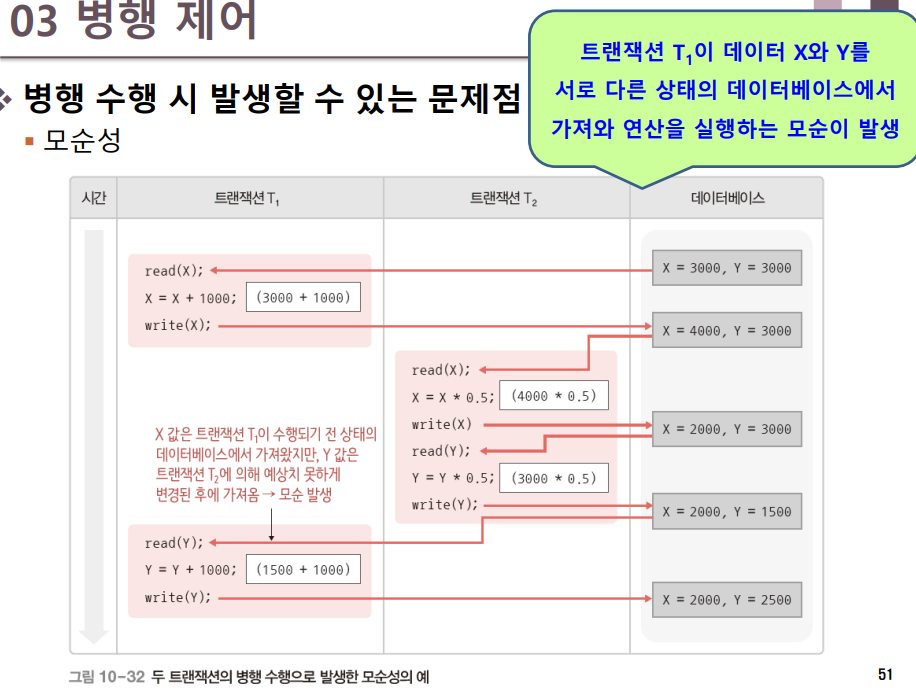
하나의 트랜잭션이 여러 데이터 변경 연산을 실행할 때, 일관성 없는 상태의 데이터베이스에서 데이터를 가져와 연산함으로써 모순된 결과가 발생하는 것이다. 여러 트랜잭션이 동시에 수행되더라도 모순성 문제가 발생하지 않고 마치 트랜잭션들이 순차적으로 수행한 것과 같은 결과 값을 얻을 수 있어야 한다.(즉, 직렬 가능한 스케줄이어야 모순성이 발생하지 않는다.)
연쇄 복귀(cascading rollback)
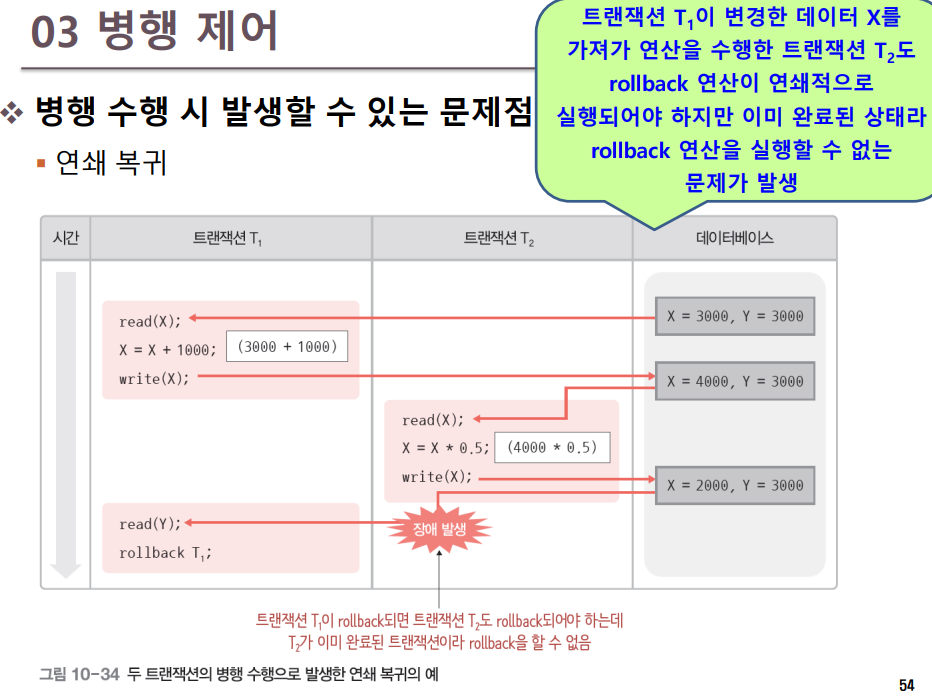
트랜잭션이 완료되기 전 장애가 발생하여 rollback 연산을 수행하면, 장애 발생 전에 이 트랜잭션이 변경한 데이터를 가져가서 변경 연산을 실행한 다른 트랜잭션에도 rollback 연산을 연쇄적으로 실행해야 한다는 것이다. 여러 트랜잭션이 동시에 수행되더라도 연쇄 복귀 문제가 발생하지 않고 마치 트랜잭션들을 순차적으로 수행한 것과 같은 결과 값을 얻을 수 있어야 한다. (즉, 직렬 가능한 스케줄이어야 하며 Casecadeless 스케줄이거나 복구 가능한 스케줄이어야 한다.)
병행 제어
앞서 병행 수행의 문제를 살펴봤다. 결국에는 문제를 해결하기 위해서는 트랜잭션 스케줄은 직렬 가능한 스케줄이고, 복구 가능한 스케줄이어야 한다. 이런 스케줄을 보장하기 위해 데이터베이스 관리 시스템은 병행 수행 시 직렬 가능성을 보장하기 위한 기법으로 병행 제어 기법을 사용한다.
병행 수행하면서도 직렬 가능성을 보장하기 위한 기법이 병행 제어 기법이다. 즉, 모든 트랜잭션이 준수하면 직렬 가능성이 보장되는 규약을 정의하고 트랜잭션들이 이 규약을 따르도록 한다. 대표적인 병행 제어 기법으로 로킹(locking) 기법이 있다.
로킹 기법(Locking Protocol)
로킹 기법의 기본 원리는 한 트랜잭션이 먼저 접근한 데이터에 대한 연산을 모두 마칠 때까지, 해당 데이터에 다른 트랜잭션이 접근하지 못하도록 상호 배제(mutual exclusion)하여 직렬 가능성을 보장한다.
기본적인 로킹 규약은 아래와 같다.
- 트랜잭션은 데이터에 접근하기 위해 먼저 lock 연산을 실행해 독점권을 획득한다. (read 혹은 write 실행 전 lock 실행)
- 다른 트랜잭션에 의해 이미 lock 연산이 실행된 데이터에는 다시 lock 연산을 실행할 수 없다.
- 독점권을 획득한 데이터에 대한 모든 연산의 수행이 끝나면 트랜잭션은 unlock 연산을 실행하여 독점권을 반납해야 한다.
로킹의 단위와 병행성의 상관관계는 아래와 같다.
- lock 연산을 실행하는 대상 데이터의 크기
- 전체 데이터베이스부터 릴레이션, 튜플, 속성까지도 가능하다.
- 로킹 단위가 커질수록 병행성은 낮아지지만 제어가 쉽다.
- 로킹 단위가 작아질수록 제어가 어렵지만 병행성이 높아진다.
위와 같은 기본 로킹 기법은 병행 수행을 제어하는 목표는 이룰 수 있지만 너무 엄격하여 효율적이지 않다. read 연산은 다른 트랜잭션이 같은 데이터에 동시에 read 연산을 실행해도 문제가 생기지 않는 점을 이용하여 효율적으로 사용할 수 있다. 즉, 트랜잭션들이 같은 데이터에 동시에 read 연산을 실행하는 것을 허용하기 위해 lock 연산을 두 가지 종류로 구분하여 사용한다.

공용 lock과 전용 lock의 양립성은 아래와 같다.
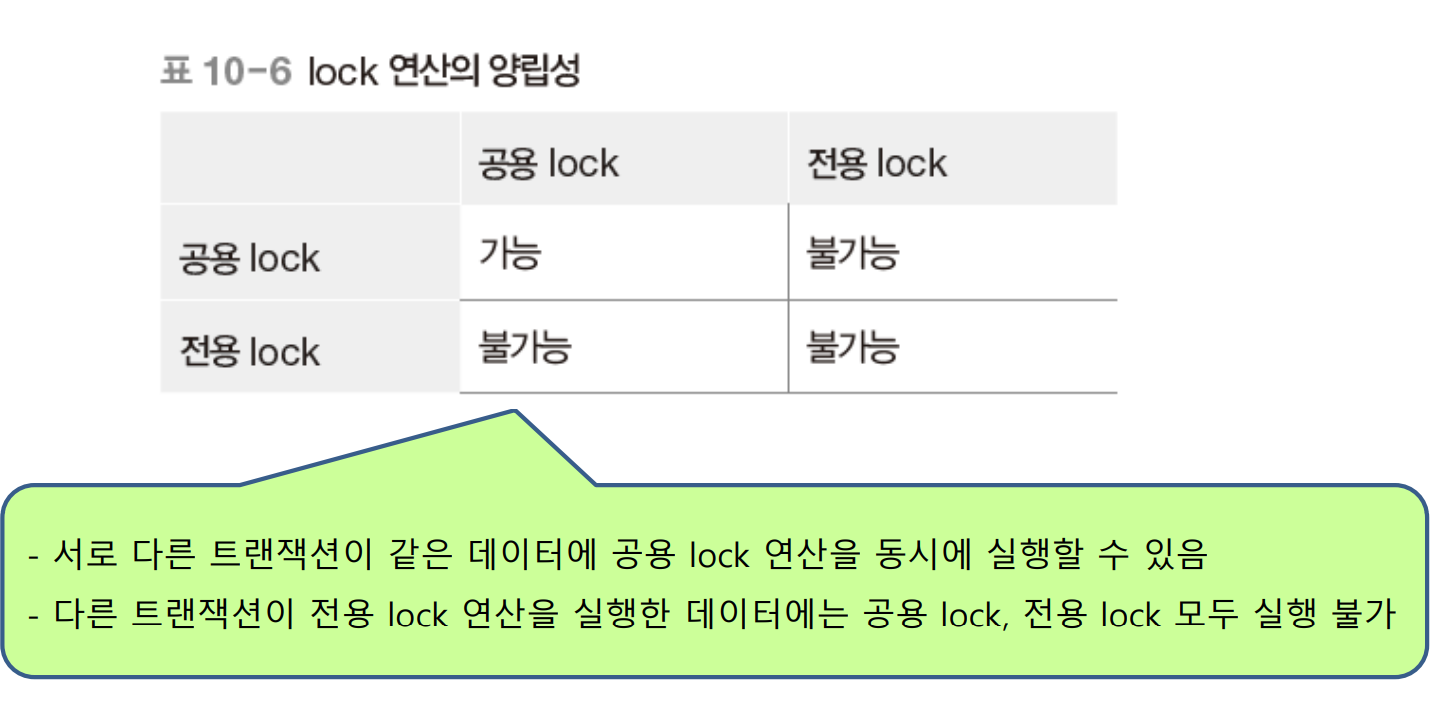
한 트랜잭션이 특정 데이터에 대해서 전용 lock 연산을 수행했다면 그 트랜잭션이 unlock을 하기 전까지 특정 데이터에 대해서 공용 lock과 전용 lock 둘 다 실행할 수 없다. 반대로 생각해보면 한 트랜잭션이 특정 데이터에 대해서 공용 lock을 수행했다면 그 특정 데이터에 대해서 다른 트랜잭션은 전용 lock을 실행할 수 없다. 만약 전용 lock을 실행하게 되면 lock 연산의 양립성이 깨지게 되기 때문이다.
2단계 로킹 규약(2 PLP; 2 Pgase Locking Protocol)
기본 로킹 규약을 따르는 스케줄은 항상 직렬 가능성이 보장된다고 할 수 없다. 기본 로킹 규약으로 직렬 가능성이 보장되지 않는 스케줄의 예시를 확인해보자.
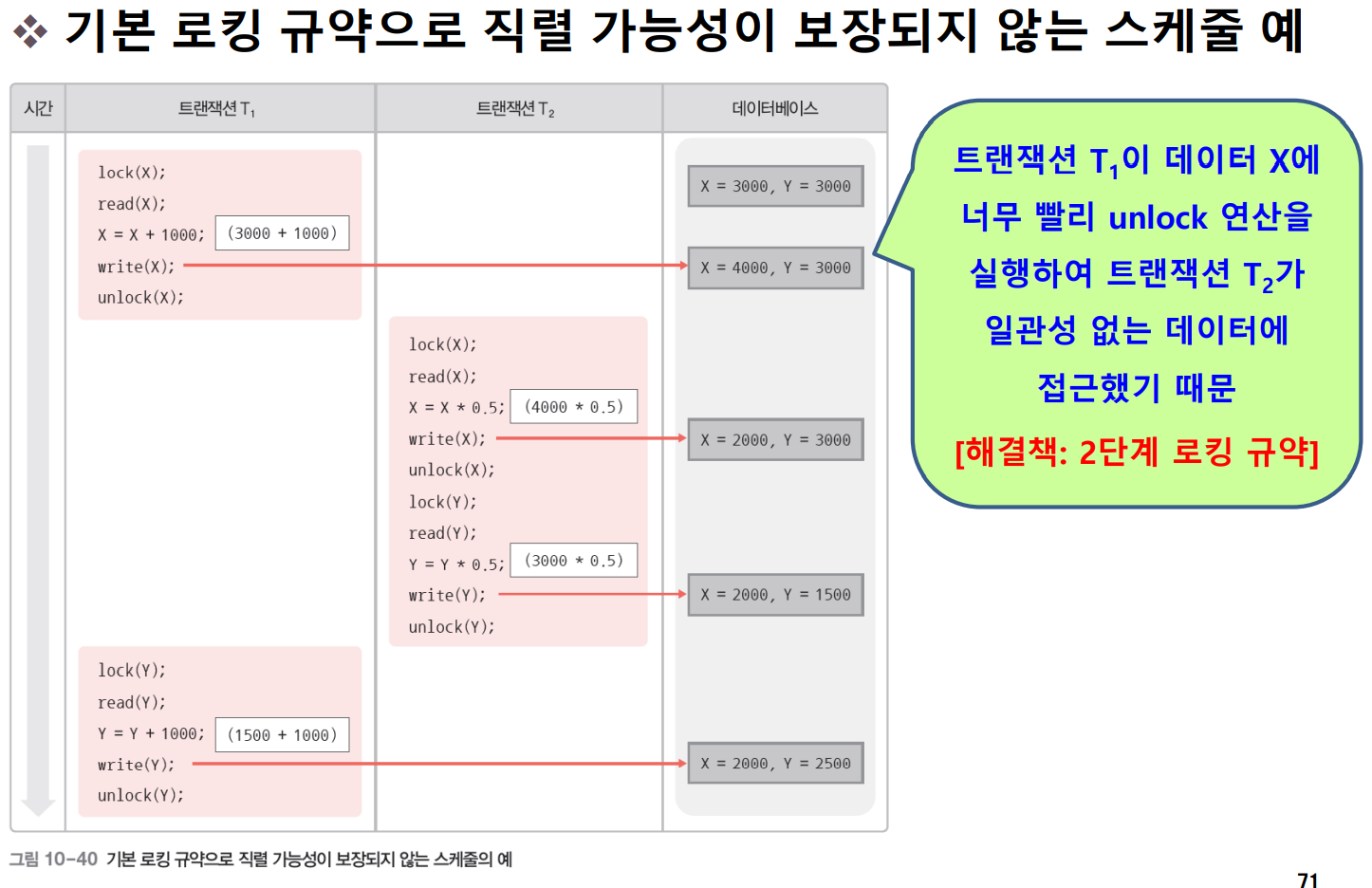
위와 같은 문제의 해결책으로 2단계 로킹 규약을 사용할 수 있다. 2단계 로킹 규약은 기본 로킹 규약의 문제를 해결하고 트랜잭션의 직렬 가능성을 보장하기 위해 lock과 unlock의 수행 시점에 대한 새로운 규약을 추가한 것이다.
2단계 로킹 규약은 아래와 같다.
- 트랜잭션이 lock, unlock 연산을 확장 단계(growth phase)와 축소 단계(shrinking phase)로 나누어 실행한다.
- 트랜잭션이 처음 수행되면 확장 단계로 들어가 lock 연산만 실행 가능하다.
- unlock 연산을 실행하면 축소 단계로 들어가 unlock 연산만 실행 가능하다.
- 트랜잭션은 첫 번째 unlock 연산 실행 전에 필요한 모든 lock 연산을 실행해야 한다.
- 2단계 로킹 규약의 두 가지 단계는 아래와 같다.

2단계 로킹 규약을 이해하기 위해 이 기법을 이용해 직렬 가능성이 보장된 스케줄의 예시를 확인해보자.

위의 예시를 보면 첫 번째 트랜잭션이 확장 단계에 들어서서 필요한 모든 데이터에 lock 연산을 수행하고 unlock을 수행한 시점부터 unlock 연산만 수행했다. 또한 두 번째 트랜잭션도 필요한 모든 데이터에 lock 연산을 수행하여 확장 단계에 진입함으로 2단계 로킹 규약을 만족했다. 이렇게 2단계 로킹 규약을 적용하면 트랜잭션 스케줄의 직렬 가능성을 보장할 수 있다. 하지만 교착 상태(deadlock)가 발생할 수 있어 이에 대한 해결책이 필요하다.
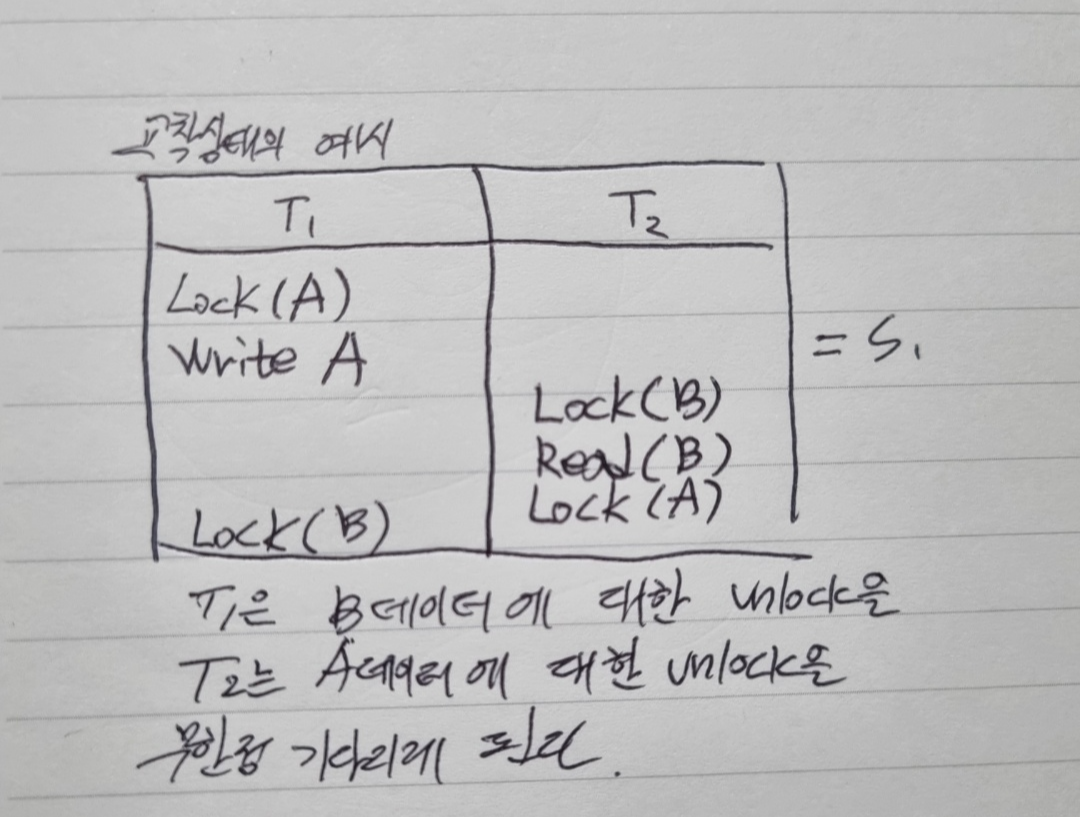
교착 상태(deadlock)
트랜잭션들이 상대가 독점하고 있는 데이터에 unlock 연산이 실행되기를 서로 기다리면서 트랜잭션의 수행을 중단하고 있는 상태이다. 교착 상태가 발생하지 않도록 예방하거나, 발생 시 빨리 탐지하여 필요한 조치를 취해야 한다.
데이터베이스 관리 시스템에서 Lock manager는 모든 lock에 대한 요청을 처리하고 lock에 대한 정보를 hash table에 저장하여 관리한다. 이러한 Lock manager는 교착 상태를 탐지하여 교착 상태가 되는 트랜잭션을 rollback 한다.
MVCC(Multi-version concurency control)
최근 많은 데이터베이스 관리 시스템은 로킹에서 오는 성능 문제를 개선하기 위해서 MVCC를 병행 제어 기법으로 사용한다. MVCC 방법은 데이터 업데이트가 있을 때 이전의 데이터를 덮어 씌우는 게 아니라 새로운 버전의 데이터를 version space(undo space)에 저장하고 링크를 생성하고 데이터를 조회할 때 트랜잭션의 시작 시점에 맞는 데이터 버전을 반환한다.
이를 위해 CSN(Commit Sequence Number)를 이용한다. 예를 들어 Transaction(start before CSN = 5) 이 있다고 했을 때, 그 트랜잭션은 CSN이 1인 데이터 버전(old_value)을 보고, Transaction(start after CSN = 5)는 CSN이 5인 데이터 버전을 보게 된다. 이 방식은 read 연산에 대한 lock 필요 없으며 로킹 기법을 사용하는 것보다 좋은 성능을 보여 준다. 다만 버전에 대한 garbage collection이 필요하다. 다음에 MVCC에 대해서 더욱 자세하게 알아보도록 하겠다.
'CS > 데이터베이스' 카테고리의 다른 글
| InnoDB 인덱스 개념과 데이터 읽기 방식 + 실습 (0) | 2023.01.28 |
|---|---|
| 데이터베이스 관리 시스템의 아키텍처(DBMS Architecture) (2) | 2022.10.15 |
| 데이터베이스 장애(failure)와 회복(recovery) (0) | 2022.10.02 |
| 견고하게 트랜잭션 스케줄(Transaction Schedules) 개념 잡기 (0) | 2022.10.01 |
| 트랜잭션(Transaction) 개념과 트랜잭션의 특성(ACID) (0) | 2022.09.30 |
일반적인 데이터베이스 개론에서 트랜잭션 개념과 회복 다음 내용이므로 순서대로 공부하는 것을 선호하신다면 데이터베이스 트랜잭션 개념과 회복까지 학습하시면 도움이 될 수 있습니다. 잘못된 부분이 있다면 피드백 부탁드립니다.
들어가기 앞서
이 글을 읽기 전에 이전에 다룬 견고하게 트랜잭션 스케줄(Transaction Schedules) 개념 잡기 를 먼저 읽는 다면 도움이 될 것이다. 일반적으로는 트랜잭션의 병행 수행에 의한 문제를 다루고, 스케줄링을 공부한 이후 병행 제어를 배운다.
하지만 반대로 나는 문제가 생기지 않는 병행 수행을 이해하기 위한 스케줄링에 대한 개념을 먼저 다루었다. 비직렬 스케줄에 따라 여러 트랜잭션을 인터리빙 방식으로 병행 수행한다면 갱신 분실, 모순성, 연쇄 복귀 등의 문제가 일어날 수 있다고 언급했었다. 이번 글에서는 그 부분에 대해서 다뤄 보도록 하겠다.
병행 수행과 병행 제어
데이터베이스 관리 시스템은 여러 사용자가 데이터베이스를 동시에 공유할 수 있도록 여러 트랜잭션이 동시에 수행되는 병행 수행(concurrency)을 지원한다. 병행 수행은 여러 트랜잭션들이 차례로 번갈아 수행되는 인터리빙 방식으로 진행된다. 또한 트랜잭션의 순서를 고려하지 않으면 데이터베이스의 일관성을 보증할 수 없다.(즉, 무결성을 보장하기 어려움) 따라서 병행 제어(concurrency control)가 필요하며 이것은 동시성 제어라고도 한다. 즉, 병행 수행 시 같은 데이터에 접근하여 연산을 실행해도 문제가 발생하지 않고 정확한 수행 결과를 얻을 수 있도록 트랜잭션의 수행을 제어하는 것을 의미한다. 다시 말하자면 병행 제어는 결국 직렬 가능한 스케줄을 만들기 위함이라 생각할 수 있다.
병행 수행의 문제
병행 수행을 특별한 제어 없이 한다면 여러 문제가 발생할 수 있다. 대표적인 문제로는 갱신 분실, 모순성, 연쇄 복귀가 있다. 가볍게 한번 알아보자.
갱신 분실(lost update)
하나의 트랜잭션이 수행한 데이터 변경 연산의 결과를 다른 트랜잭션이 덮어써서 변경 연산이 무효화되는 것이다. 예를 들어 데이터 X에 1000을 더하는 트랜잭션 T₁과 데이터 X를 50% 감소시키는 트랜잭션 T₂ 가 병행 수행될 때, 아래처럼 T₁ 의 write(X) 연산이 무효화된 것을 알 수 있다. 갱신 분실을 예방하기 위해선 여러 트랜잭션이 동시에 수행되더라도 마치 트랜잭션들을 순차적으로 수행한 것과 같은 결과 값을 얻을 수 있어야 한다.(즉, 직렬 가능한 스케줄이어야 갱신 분실이 발생하지 않는다.)
모순성(inconsistency)
하나의 트랜잭션이 여러 데이터 변경 연산을 실행할 때, 일관성 없는 상태의 데이터베이스에서 데이터를 가져와 연산함으로써 모순된 결과가 발생하는 것이다. 여러 트랜잭션이 동시에 수행되더라도 모순성 문제가 발생하지 않고 마치 트랜잭션들이 순차적으로 수행한 것과 같은 결과 값을 얻을 수 있어야 한다.(즉, 직렬 가능한 스케줄이어야 모순성이 발생하지 않는다.)
연쇄 복귀(cascading rollback)
트랜잭션이 완료되기 전 장애가 발생하여 rollback 연산을 수행하면, 장애 발생 전에 이 트랜잭션이 변경한 데이터를 가져가서 변경 연산을 실행한 다른 트랜잭션에도 rollback 연산을 연쇄적으로 실행해야 한다는 것이다. 여러 트랜잭션이 동시에 수행되더라도 연쇄 복귀 문제가 발생하지 않고 마치 트랜잭션들을 순차적으로 수행한 것과 같은 결과 값을 얻을 수 있어야 한다. (즉, 직렬 가능한 스케줄이어야 하며 Casecadeless 스케줄이거나 복구 가능한 스케줄이어야 한다.)
병행 제어
앞서 병행 수행의 문제를 살펴봤다. 결국에는 문제를 해결하기 위해서는 트랜잭션 스케줄은 직렬 가능한 스케줄이고, 복구 가능한 스케줄이어야 한다. 이런 스케줄을 보장하기 위해 데이터베이스 관리 시스템은 병행 수행 시 직렬 가능성을 보장하기 위한 기법으로 병행 제어 기법을 사용한다.
병행 수행하면서도 직렬 가능성을 보장하기 위한 기법이 병행 제어 기법이다. 즉, 모든 트랜잭션이 준수하면 직렬 가능성이 보장되는 규약을 정의하고 트랜잭션들이 이 규약을 따르도록 한다. 대표적인 병행 제어 기법으로 로킹(locking) 기법이 있다.
로킹 기법(Locking Protocol)
로킹 기법의 기본 원리는 한 트랜잭션이 먼저 접근한 데이터에 대한 연산을 모두 마칠 때까지, 해당 데이터에 다른 트랜잭션이 접근하지 못하도록 상호 배제(mutual exclusion)하여 직렬 가능성을 보장한다.
기본적인 로킹 규약은 아래와 같다.
- 트랜잭션은 데이터에 접근하기 위해 먼저 lock 연산을 실행해 독점권을 획득한다. (read 혹은 write 실행 전 lock 실행)
- 다른 트랜잭션에 의해 이미 lock 연산이 실행된 데이터에는 다시 lock 연산을 실행할 수 없다.
- 독점권을 획득한 데이터에 대한 모든 연산의 수행이 끝나면 트랜잭션은 unlock 연산을 실행하여 독점권을 반납해야 한다.
로킹의 단위와 병행성의 상관관계는 아래와 같다.
- lock 연산을 실행하는 대상 데이터의 크기
- 전체 데이터베이스부터 릴레이션, 튜플, 속성까지도 가능하다.
- 로킹 단위가 커질수록 병행성은 낮아지지만 제어가 쉽다.
- 로킹 단위가 작아질수록 제어가 어렵지만 병행성이 높아진다.
위와 같은 기본 로킹 기법은 병행 수행을 제어하는 목표는 이룰 수 있지만 너무 엄격하여 효율적이지 않다. read 연산은 다른 트랜잭션이 같은 데이터에 동시에 read 연산을 실행해도 문제가 생기지 않는 점을 이용하여 효율적으로 사용할 수 있다. 즉, 트랜잭션들이 같은 데이터에 동시에 read 연산을 실행하는 것을 허용하기 위해 lock 연산을 두 가지 종류로 구분하여 사용한다.
공용 lock과 전용 lock의 양립성은 아래와 같다.
한 트랜잭션이 특정 데이터에 대해서 전용 lock 연산을 수행했다면 그 트랜잭션이 unlock을 하기 전까지 특정 데이터에 대해서 공용 lock과 전용 lock 둘 다 실행할 수 없다. 반대로 생각해보면 한 트랜잭션이 특정 데이터에 대해서 공용 lock을 수행했다면 그 특정 데이터에 대해서 다른 트랜잭션은 전용 lock을 실행할 수 없다. 만약 전용 lock을 실행하게 되면 lock 연산의 양립성이 깨지게 되기 때문이다.
2단계 로킹 규약(2 PLP; 2 Pgase Locking Protocol)
기본 로킹 규약을 따르는 스케줄은 항상 직렬 가능성이 보장된다고 할 수 없다. 기본 로킹 규약으로 직렬 가능성이 보장되지 않는 스케줄의 예시를 확인해보자.
위와 같은 문제의 해결책으로 2단계 로킹 규약을 사용할 수 있다. 2단계 로킹 규약은 기본 로킹 규약의 문제를 해결하고 트랜잭션의 직렬 가능성을 보장하기 위해 lock과 unlock의 수행 시점에 대한 새로운 규약을 추가한 것이다.
2단계 로킹 규약은 아래와 같다.
- 트랜잭션이 lock, unlock 연산을 확장 단계(growth phase)와 축소 단계(shrinking phase)로 나누어 실행한다.
- 트랜잭션이 처음 수행되면 확장 단계로 들어가 lock 연산만 실행 가능하다.
- unlock 연산을 실행하면 축소 단계로 들어가 unlock 연산만 실행 가능하다.
- 트랜잭션은 첫 번째 unlock 연산 실행 전에 필요한 모든 lock 연산을 실행해야 한다.
- 2단계 로킹 규약의 두 가지 단계는 아래와 같다.
2단계 로킹 규약을 이해하기 위해 이 기법을 이용해 직렬 가능성이 보장된 스케줄의 예시를 확인해보자.
위의 예시를 보면 첫 번째 트랜잭션이 확장 단계에 들어서서 필요한 모든 데이터에 lock 연산을 수행하고 unlock을 수행한 시점부터 unlock 연산만 수행했다. 또한 두 번째 트랜잭션도 필요한 모든 데이터에 lock 연산을 수행하여 확장 단계에 진입함으로 2단계 로킹 규약을 만족했다. 이렇게 2단계 로킹 규약을 적용하면 트랜잭션 스케줄의 직렬 가능성을 보장할 수 있다. 하지만 교착 상태(deadlock)가 발생할 수 있어 이에 대한 해결책이 필요하다.
교착 상태(deadlock)
트랜잭션들이 상대가 독점하고 있는 데이터에 unlock 연산이 실행되기를 서로 기다리면서 트랜잭션의 수행을 중단하고 있는 상태이다. 교착 상태가 발생하지 않도록 예방하거나, 발생 시 빨리 탐지하여 필요한 조치를 취해야 한다.
데이터베이스 관리 시스템에서 Lock manager는 모든 lock에 대한 요청을 처리하고 lock에 대한 정보를 hash table에 저장하여 관리한다. 이러한 Lock manager는 교착 상태를 탐지하여 교착 상태가 되는 트랜잭션을 rollback 한다.
MVCC(Multi-version concurency control)
최근 많은 데이터베이스 관리 시스템은 로킹에서 오는 성능 문제를 개선하기 위해서 MVCC를 병행 제어 기법으로 사용한다. MVCC 방법은 데이터 업데이트가 있을 때 이전의 데이터를 덮어 씌우는 게 아니라 새로운 버전의 데이터를 version space(undo space)에 저장하고 링크를 생성하고 데이터를 조회할 때 트랜잭션의 시작 시점에 맞는 데이터 버전을 반환한다.
이를 위해 CSN(Commit Sequence Number)를 이용한다. 예를 들어 Transaction(start before CSN = 5) 이 있다고 했을 때, 그 트랜잭션은 CSN이 1인 데이터 버전(old_value)을 보고, Transaction(start after CSN = 5)는 CSN이 5인 데이터 버전을 보게 된다. 이 방식은 read 연산에 대한 lock 필요 없으며 로킹 기법을 사용하는 것보다 좋은 성능을 보여 준다. 다만 버전에 대한 garbage collection이 필요하다. 다음에 MVCC에 대해서 더욱 자세하게 알아보도록 하겠다.
'CS > 데이터베이스' 카테고리의 다른 글
| InnoDB 인덱스 개념과 데이터 읽기 방식 + 실습 (0) | 2023.01.28 |
|---|---|
| 데이터베이스 관리 시스템의 아키텍처(DBMS Architecture) (2) | 2022.10.15 |
| 데이터베이스 장애(failure)와 회복(recovery) (0) | 2022.10.02 |
| 견고하게 트랜잭션 스케줄(Transaction Schedules) 개념 잡기 (0) | 2022.10.01 |
| 트랜잭션(Transaction) 개념과 트랜잭션의 특성(ACID) (0) | 2022.09.30 |