
일반적인 데이터베이스 개론에서 트랜잭션 개념과 회복 다음 내용이므로 순서대로 공부하는 것을 선호하신다면 데이터베이스 트랜잭션 개념과 회복까지 학습하시면 도움이 될 수 있습니다. 잘못된 부분이 있다면 피드백 부탁드립니다.
스케줄이 없는 세상

만약 컴퓨터과학에서 스케줄링이 없었다면 세상은 위와 같을 것이다. 운영체제를 배울 때도 스케줄링은 소중하구나 느꼈는데, 트랜잭션 스케줄링을 공부할 때도 다시 한번 소중함을 느낄 수 있었다.
트랜잭션 스케줄(Transaction Schedules) 이란?
데이터베이스의 일관적인 상태를 유지하기 위해서 동시에 실행되는 트랜잭션(병행 수행)들의 연산 순서를 정하는 것을 의미한다. 연산 순서에 따라서 결과가 달라지기 때문에 병행 수행을 하기 위해서는 스케줄이 중요하다. 병행 수행에서 트랜잭션들은 차례로 번갈아 가면서 수행되는 인터리빙 방식으로 진행된다.

트랜잭션들의 연산을 실행하는 순서인 트랜잭션 스케줄은 세 가지 유형이 존재한다.
| 스케줄 | 의미 |
| 직렬 스케줄(serial schedule) | 인터리빙 방식을 이용하지 않고 각 트랜잭션별로 연산들을 순차적으로 실행한다. |
| 비직렬 스케줄(nonserial schedule) | 인터리빙 방식을 이용하여 트랜잭션들을 병해해서 수행시키는 것 |
| 직렬 가능 스케줄(serializable schedule) | 직렬 스케줄과 같이 정확한 결과를 생성하는 비직렬 스케줄 |
정확한 결과를 만드는 스케줄은 serial schedule이고 격리성이 가장 높다. 항상 consistent 한 결과를 생성하지만 순차적으로 실행하기 때문에 처리량의 관점에서는 효율적이지 못하다. 스케줄이 직렬 실행은 아니지만 직렬 스케줄과 같은 결과를 내는 스케줄을 serializable이라 한다. 즉, 결과가 equivalent 하다. serializable를 계산하기 위해선 conflict serializabillty와 view serializability 두 가지 개념을 알아야 한다.
직렬 스케줄(serial schedule)
직렬 스케줄은 인터리빙 방식을 이용하지 않고 각 트랜잭션 별로 연산들을 순차적으로 실행시키는 것이다. 모든 트랜잭션이 완료될 때까지 다른 트랜잭션의 방해를 받지 않고 독립적으로 수행된다. 즉, 항상 정확한 결과를 만들며 격리성이 높다. 위에 직접 그린 그림에서 S₁ 이 직렬 스케줄의 예시이다. 만약 T₂ 의 모든 연산이 먼저 실행돼도 결과는 950으로 같다.
참고로 T₁ 은 50을 더하고, T₂ 는 100을 감소시킨다.
위에서 잠깐 언급한 것처럼, 인터리빙을 사용하지 않고, 독립적으로 수행하기 때문에 병행 수행이라 할 수 없다. 즉, 데이터베이스의 처리량의 관점에서 효율적인 방식은 아니기 때문에 잘 사용하지 않는다.
비직렬 스케줄(nonserial schedule)
비직렬 스케줄은 인터리빙 방식을 이용해서 트랜잭션을 병행해서 수행시키는 것이다. 비직렬 스케줄에 따라 여러 트랜잭션을 병행 수행하면 갱신 분실, 모순성, 연쇄 복귀 등의 문제가 발생할 수 있다. 이러한 문제는 다음에 따로 다루도록 하겠다. 여기서는 그냥 최종 수행 결과의 정확성을 보장할 수 없다는 것만 기억하자. 예시는 위에 직접 그린 그림에서 S₂ 를 확인하면 된다. 굳이 어떤 문제인지 분석해보자면 1번 트랜잭션의 갱신을 분실했고, 모순성의 가능성이 있다. 또한 가장 중요한 트랜잭션 일관성 또한 무너지게 된다.
직렬 가능 스케줄(serializable schedule)
살짝 긴장하고 생각해야 한다. 헷갈리는 부분이 있다.
직렬 가능 스케줄은 직렬 스케줄에 따라 수행한 것과 같이 정확한 결과를 생성하는 비직렬 스케줄이다. 이렇게 정확한 결과를 보장하는 것은 serial schedule과 equivalent 하다고 한다. 쉽게 설명하자면 모든 트랜잭션을 순차적으로 인터리빙 없이 실행한 결과를 내는 비직렬 스케줄이다. 즉, 제일 성능도 좋고 일관성을 유지할 수 있다. 다만 달리 생각해보면 그만큼 많은 개념이 존재할 것이다. 여러 개념을 파악해보자. 직렬 가능한 스케줄은 다음과 같이 두 개가 있고 포함관계이다.
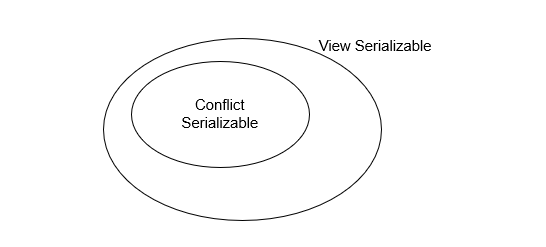
충돌 직렬 가능(conflict serializable)한 스케줄
동일한 데이터에 대해서 두 트랜잭션이 있다고 가정했을 때, 적어도 하나의 연산이 write인 경우 충돌(conflicting)이라 할 수 있다.

충돌이 나지 않는 연산(non-conflicting instruction)들의 순서를 변경하여 새로운 스케줄을 만들 수 있다면 기존 스케줄과 새로운 스케줄은 충돌 동등하다. 그중에서 기존 스케줄이 직렬 스케줄과 충돌 동등하다면 기존 스케줄은 충돌 직렬 가능하다고 한다. 쉬운 이해를 위해서 정리해보겠다.
만약 스케줄 S의 non-coflicting instruction을 swap 해서 S'를 만들 수 있는 경우,
S와 S' 는 conflict equivalent 라고 한다.
특별하게 스케줄 S가 serial schedule과 conflict equivalent하면 S는 conflict serializable 하다.
즉, S'가 serial schedule 인 경우에는 S는 conflict serializable 하다.조금 더 쉽게 정리하겠다.
1. 스케줄 하나가 충돌이 안나는 연산들을 스왑했다. (S의 충돌이 나지 않는 연산을 스왑)
2. 변경해서 새로운 스케줄이 나왔다. (S'이 생기고 S와 S`은 충돌 동등하다 표현)
3. 근데 새로운 스케줄이 직렬이다. (특히, S가 직렬 스케줄과 충돌 동등)
4. 그렇다면 S는 충돌 직렬 가능한 스케줄이라고 말할 수 있다.
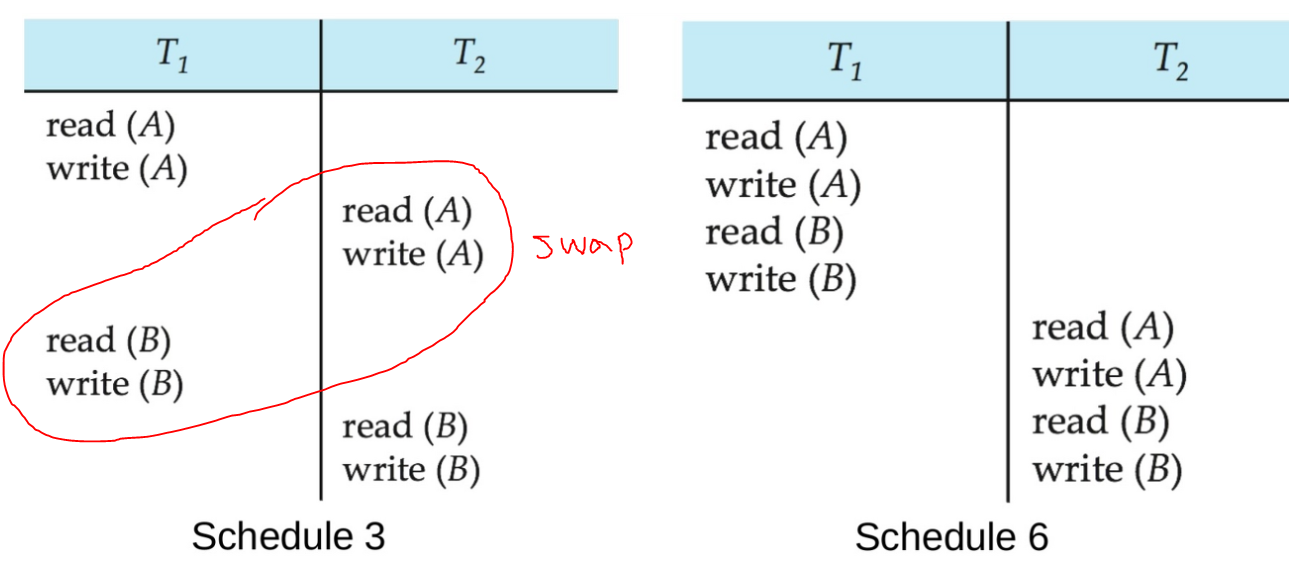
예시를 통해 이해해보자. 어느 한 스케줄의 충돌이 없는 연산의 순서를 조작해서 직렬 스케줄을 만들 수 있다면 그 스케줄은 직렬 가능 스케줄이며, 엄밀히는 충돌 직렬 가능한 스케줄이다. 아래 Schedule 3은 충돌 직렬 가능한 스케줄이다. 왜냐하면 T₁와 T₂의 충돌하지 않는 연산을 스왑 하여 직렬 스케줄을 변환할 수 있고, 서로 결과가 동등하기 때문이다.
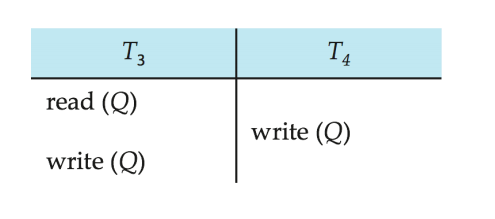
위와 같은 경우에는 충돌하지 않는 연산을 스왑 할 수 없기 때문에 충돌 직렬이 불가능하며, 충돌 직렬 가능하지 않은 스케줄이라 한다.
용어가 많이 헷갈리지만. 여기까지 읽느라 고생하셨습니다. 이제 시작이니 조금만 더 파이팅해 봅시다.
Precedence graph를 이용한 충돌 직렬 가능성(conflict serializabillity) 검증
그런 게 있구나 하고 넘어가도 무방하다. 필자는 이왕 하는 김에 같이 공부해봤다. 위에서 봤던 충돌 직렬 가능한 스케줄의 성질을 아울러 충돌 직렬 가능성이라고 한다. 즉, 충돌 직렬 가능성이 존재해야 충돌 직렬 가능한 것이다.
Precedence graph는 충돌 그래프 혹은 conflict serializabillity 그래프라고도 하는 우선순위 그래프다. 데이터베이스에서 동시성을 제어하는 맥락에서 사용된다. 긴장을 풀기 위해서 그림부터 보고 안도감을 느껴보자.
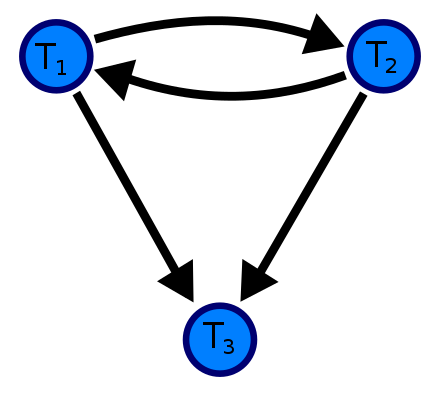
별로 안도감이 안 생긴다. 이것은 아래 트랜잭션 스케줄을 통해 그려졌다.

S = R1(A) W2(A) Com.2 W1(A) Com.1 W3(A) Com.3필자는 "스케줄 S는 A를 읽어오는 첫 번째 Read, A를 쓰는 두 번째 Write, 두 번째 커밋, A를 쓰는 첫 번째 Write, 첫 번째 커밋, A를 쓰는 세 번째 Write, 세 번째 커밋"으로 해석했다.
충돌 직렬 가능성을 테스트하는 알고리즘은 아래와 같다.
- 스케줄 S에 참여하는 각 트랜잭션 Tx에 대해서 우선순위 그래프에 Ti 노드를 생성한다. 즉, 우선순위 그래프에 T₁, T₂, T₃ 노드를 만든다.
- Ti가 write_item(X)를 수행한 후, Tj가 read_item(X)를 실행하는 스케줄 S 각각의 경우에 대해서 우선순위 그래프에서 간선 (Ti → Tj)을 만든다. 위의 예제에서는 write 이후 read가 없기 때문에 아무 일도 일어나지 않는다.
- Ti가 read_item(X)를 수행한 후, Tj가 write_item(X)를 실행하는 스케줄 S 각각의 경우에 대해서 우선 순위 그래프에서 간선 (Ti → Tj)을 만든다. 위의 예제에서는 결과로 T₁에서 T₂로 향하는 간선이 생긴다. 왜냐하면 T₂가 W1(A)를 갖기 전에 T₁에서 R1(A)를 갖기 때문이다.
- Ti가 write_item(X)를 수행한 후, Tj가 write_item(X)를 실행하는 스케줄 S 각각의 경우에 대해서 우선 순위 그래프에서 간선 (Ti → Tj)을 만든다. 위의 예제에서는 결과로 T₂에서 T₁, T₂에서 T₃ 그리고 T₁에서 T₃로 방향 간선이 생긴다.
- 스케줄 S는 우선순위 그래프에 순환이 없는 경우에 직렬 가능하다. 위의 예제는 T₁과 T₂는 하나의 순환을 구성하고 있으므로 위의 예시는 충돌 직렬 가능성이 없다. 즉, 충돌 직렬 가능할 수 없다.
뷰 직렬 가능(View Serializable)한 스케줄
스케줄 S와 S'이 아래의 조건을 모두 만족하면 view equivalent 하다고 한다.
- initial read: 만약 S의 트랜잭션 T₁이 Q의 초기값을 read 했다면, S'에서도 T₁은 Q의 초기값을 read 해야 한다.
- same read: 만약 S의 T₁이 T₂로부터 생성된 Q를 read 했다면, S'에서도 T₁은 T₂로부터 생성된 Q값을 읽어야 한다.
- final write: 만약 S의 T₁이 final write(Q)를 했다면 S'에서도 T₁이 final write(Q)를 해야 한다.
그중 특히 S가 serial schedule과 view equivalent 하면 S는 뷰 직렬 가능한 스케줄이다.

모든 충돌 직렬 가능한 스케줄은 뷰 직렬 가능하다. 즉, 충돌 직렬은 뷰 직렬의 부분 집합이다. 위 예제는 뷰 직렬 가능하지만, 충돌 직렬 가능하지 않은 예제이다. 위와 같은 케이스의 특징으로는 T₂₈처럼 blind write를 가지고 있다.

복구 가능한 스케줄(Recoverable Schedule)
스케줄은 serializable 해야 하고, 복구 가능해야 한다. 만약에 T₂가 T₁에 의해 변경된 데이터를 사용할 때, T₁이 commit 되기 전에 T₂는 commit 하면 안 된다. 그래야 T₁이 abort 될 때, T₂도 abort 될 수 있다.
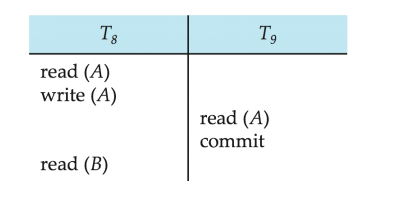
위 케이스는 복구 가능하지 않은 스케줄이다. 복구하기 위해서 T₈의 commit이 먼저 일어나야 한다. 하지만 위의 경우는 T₉이 A를 read 한 이후에 commit 했다. 이 상황에서는 T₈이 abort 되면 T₉는 abort 될 수 없기 때문에 데이터베이스가 inconsistent 해진다. 복구 가능 스케줄은 단순히 T₉의 commit보다 T₈의 commit을 먼저 하는 것으로 성립된다.
캐스케이드 스케줄(Cascade Schedule)

T₁₀ 트랜잭션이 실패하면 T₁₁, T₁₂ 모두 롤백돼야 한다. 이것을 cascading rollback이라 한다. 이러한 특징을 가진 스케줄을 캐스케이드 스케줄이라 하는데, 캐스케이드 스케줄은 복구 가능하지 않은 스케줄을 만든다. Cascadeless 스케줄은 다른 트랜잭션이 읽기 전에 commit을 해야 한다. 결국 Cascadeless 스케줄은 모두 복구 가능한 스케줄이다.
'CS > 데이터베이스' 카테고리의 다른 글
| InnoDB 인덱스 개념과 데이터 읽기 방식 + 실습 (0) | 2023.01.28 |
|---|---|
| 데이터베이스 관리 시스템의 아키텍처(DBMS Architecture) (2) | 2022.10.15 |
| 트랜잭션의 병행 수행(concurrency)와 병행 제어(concurrency control) (0) | 2022.10.09 |
| 데이터베이스 장애(failure)와 회복(recovery) (0) | 2022.10.02 |
| 트랜잭션(Transaction) 개념과 트랜잭션의 특성(ACID) (0) | 2022.09.30 |
일반적인 데이터베이스 개론에서 트랜잭션 개념과 회복 다음 내용이므로 순서대로 공부하는 것을 선호하신다면 데이터베이스 트랜잭션 개념과 회복까지 학습하시면 도움이 될 수 있습니다. 잘못된 부분이 있다면 피드백 부탁드립니다.
스케줄이 없는 세상
만약 컴퓨터과학에서 스케줄링이 없었다면 세상은 위와 같을 것이다. 운영체제를 배울 때도 스케줄링은 소중하구나 느꼈는데, 트랜잭션 스케줄링을 공부할 때도 다시 한번 소중함을 느낄 수 있었다.
트랜잭션 스케줄(Transaction Schedules) 이란?
데이터베이스의 일관적인 상태를 유지하기 위해서 동시에 실행되는 트랜잭션(병행 수행)들의 연산 순서를 정하는 것을 의미한다. 연산 순서에 따라서 결과가 달라지기 때문에 병행 수행을 하기 위해서는 스케줄이 중요하다. 병행 수행에서 트랜잭션들은 차례로 번갈아 가면서 수행되는 인터리빙 방식으로 진행된다.
트랜잭션들의 연산을 실행하는 순서인 트랜잭션 스케줄은 세 가지 유형이 존재한다.
| 스케줄 | 의미 |
| 직렬 스케줄(serial schedule) | 인터리빙 방식을 이용하지 않고 각 트랜잭션별로 연산들을 순차적으로 실행한다. |
| 비직렬 스케줄(nonserial schedule) | 인터리빙 방식을 이용하여 트랜잭션들을 병해해서 수행시키는 것 |
| 직렬 가능 스케줄(serializable schedule) | 직렬 스케줄과 같이 정확한 결과를 생성하는 비직렬 스케줄 |
정확한 결과를 만드는 스케줄은 serial schedule이고 격리성이 가장 높다. 항상 consistent 한 결과를 생성하지만 순차적으로 실행하기 때문에 처리량의 관점에서는 효율적이지 못하다. 스케줄이 직렬 실행은 아니지만 직렬 스케줄과 같은 결과를 내는 스케줄을 serializable이라 한다. 즉, 결과가 equivalent 하다. serializable를 계산하기 위해선 conflict serializabillty와 view serializability 두 가지 개념을 알아야 한다.
직렬 스케줄(serial schedule)
직렬 스케줄은 인터리빙 방식을 이용하지 않고 각 트랜잭션 별로 연산들을 순차적으로 실행시키는 것이다. 모든 트랜잭션이 완료될 때까지 다른 트랜잭션의 방해를 받지 않고 독립적으로 수행된다. 즉, 항상 정확한 결과를 만들며 격리성이 높다. 위에 직접 그린 그림에서 S₁ 이 직렬 스케줄의 예시이다. 만약 T₂ 의 모든 연산이 먼저 실행돼도 결과는 950으로 같다.
참고로 T₁ 은 50을 더하고, T₂ 는 100을 감소시킨다.
위에서 잠깐 언급한 것처럼, 인터리빙을 사용하지 않고, 독립적으로 수행하기 때문에 병행 수행이라 할 수 없다. 즉, 데이터베이스의 처리량의 관점에서 효율적인 방식은 아니기 때문에 잘 사용하지 않는다.
비직렬 스케줄(nonserial schedule)
비직렬 스케줄은 인터리빙 방식을 이용해서 트랜잭션을 병행해서 수행시키는 것이다. 비직렬 스케줄에 따라 여러 트랜잭션을 병행 수행하면 갱신 분실, 모순성, 연쇄 복귀 등의 문제가 발생할 수 있다. 이러한 문제는 다음에 따로 다루도록 하겠다. 여기서는 그냥 최종 수행 결과의 정확성을 보장할 수 없다는 것만 기억하자. 예시는 위에 직접 그린 그림에서 S₂ 를 확인하면 된다. 굳이 어떤 문제인지 분석해보자면 1번 트랜잭션의 갱신을 분실했고, 모순성의 가능성이 있다. 또한 가장 중요한 트랜잭션 일관성 또한 무너지게 된다.
직렬 가능 스케줄(serializable schedule)
살짝 긴장하고 생각해야 한다. 헷갈리는 부분이 있다.
직렬 가능 스케줄은 직렬 스케줄에 따라 수행한 것과 같이 정확한 결과를 생성하는 비직렬 스케줄이다. 이렇게 정확한 결과를 보장하는 것은 serial schedule과 equivalent 하다고 한다. 쉽게 설명하자면 모든 트랜잭션을 순차적으로 인터리빙 없이 실행한 결과를 내는 비직렬 스케줄이다. 즉, 제일 성능도 좋고 일관성을 유지할 수 있다. 다만 달리 생각해보면 그만큼 많은 개념이 존재할 것이다. 여러 개념을 파악해보자. 직렬 가능한 스케줄은 다음과 같이 두 개가 있고 포함관계이다.
충돌 직렬 가능(conflict serializable)한 스케줄
동일한 데이터에 대해서 두 트랜잭션이 있다고 가정했을 때, 적어도 하나의 연산이 write인 경우 충돌(conflicting)이라 할 수 있다.
충돌이 나지 않는 연산(non-conflicting instruction)들의 순서를 변경하여 새로운 스케줄을 만들 수 있다면 기존 스케줄과 새로운 스케줄은 충돌 동등하다. 그중에서 기존 스케줄이 직렬 스케줄과 충돌 동등하다면 기존 스케줄은 충돌 직렬 가능하다고 한다. 쉬운 이해를 위해서 정리해보겠다.
만약 스케줄 S의 non-coflicting instruction을 swap 해서 S'를 만들 수 있는 경우,
S와 S' 는 conflict equivalent 라고 한다.
특별하게 스케줄 S가 serial schedule과 conflict equivalent하면 S는 conflict serializable 하다.
즉, S'가 serial schedule 인 경우에는 S는 conflict serializable 하다.조금 더 쉽게 정리하겠다.
1. 스케줄 하나가 충돌이 안나는 연산들을 스왑했다. (S의 충돌이 나지 않는 연산을 스왑)
2. 변경해서 새로운 스케줄이 나왔다. (S'이 생기고 S와 S`은 충돌 동등하다 표현)
3. 근데 새로운 스케줄이 직렬이다. (특히, S가 직렬 스케줄과 충돌 동등)
4. 그렇다면 S는 충돌 직렬 가능한 스케줄이라고 말할 수 있다.
예시를 통해 이해해보자. 어느 한 스케줄의 충돌이 없는 연산의 순서를 조작해서 직렬 스케줄을 만들 수 있다면 그 스케줄은 직렬 가능 스케줄이며, 엄밀히는 충돌 직렬 가능한 스케줄이다. 아래 Schedule 3은 충돌 직렬 가능한 스케줄이다. 왜냐하면 T₁와 T₂의 충돌하지 않는 연산을 스왑 하여 직렬 스케줄을 변환할 수 있고, 서로 결과가 동등하기 때문이다.
위와 같은 경우에는 충돌하지 않는 연산을 스왑 할 수 없기 때문에 충돌 직렬이 불가능하며, 충돌 직렬 가능하지 않은 스케줄이라 한다.
용어가 많이 헷갈리지만. 여기까지 읽느라 고생하셨습니다. 이제 시작이니 조금만 더 파이팅해 봅시다.
Precedence graph를 이용한 충돌 직렬 가능성(conflict serializabillity) 검증
그런 게 있구나 하고 넘어가도 무방하다. 필자는 이왕 하는 김에 같이 공부해봤다. 위에서 봤던 충돌 직렬 가능한 스케줄의 성질을 아울러 충돌 직렬 가능성이라고 한다. 즉, 충돌 직렬 가능성이 존재해야 충돌 직렬 가능한 것이다.
Precedence graph는 충돌 그래프 혹은 conflict serializabillity 그래프라고도 하는 우선순위 그래프다. 데이터베이스에서 동시성을 제어하는 맥락에서 사용된다. 긴장을 풀기 위해서 그림부터 보고 안도감을 느껴보자.
별로 안도감이 안 생긴다. 이것은 아래 트랜잭션 스케줄을 통해 그려졌다.
S = R1(A) W2(A) Com.2 W1(A) Com.1 W3(A) Com.3필자는 "스케줄 S는 A를 읽어오는 첫 번째 Read, A를 쓰는 두 번째 Write, 두 번째 커밋, A를 쓰는 첫 번째 Write, 첫 번째 커밋, A를 쓰는 세 번째 Write, 세 번째 커밋"으로 해석했다.
충돌 직렬 가능성을 테스트하는 알고리즘은 아래와 같다.
- 스케줄 S에 참여하는 각 트랜잭션 Tx에 대해서 우선순위 그래프에 Ti 노드를 생성한다. 즉, 우선순위 그래프에 T₁, T₂, T₃ 노드를 만든다.
- Ti가 write_item(X)를 수행한 후, Tj가 read_item(X)를 실행하는 스케줄 S 각각의 경우에 대해서 우선순위 그래프에서 간선 (Ti → Tj)을 만든다. 위의 예제에서는 write 이후 read가 없기 때문에 아무 일도 일어나지 않는다.
- Ti가 read_item(X)를 수행한 후, Tj가 write_item(X)를 실행하는 스케줄 S 각각의 경우에 대해서 우선 순위 그래프에서 간선 (Ti → Tj)을 만든다. 위의 예제에서는 결과로 T₁에서 T₂로 향하는 간선이 생긴다. 왜냐하면 T₂가 W1(A)를 갖기 전에 T₁에서 R1(A)를 갖기 때문이다.
- Ti가 write_item(X)를 수행한 후, Tj가 write_item(X)를 실행하는 스케줄 S 각각의 경우에 대해서 우선 순위 그래프에서 간선 (Ti → Tj)을 만든다. 위의 예제에서는 결과로 T₂에서 T₁, T₂에서 T₃ 그리고 T₁에서 T₃로 방향 간선이 생긴다.
- 스케줄 S는 우선순위 그래프에 순환이 없는 경우에 직렬 가능하다. 위의 예제는 T₁과 T₂는 하나의 순환을 구성하고 있으므로 위의 예시는 충돌 직렬 가능성이 없다. 즉, 충돌 직렬 가능할 수 없다.
뷰 직렬 가능(View Serializable)한 스케줄
스케줄 S와 S'이 아래의 조건을 모두 만족하면 view equivalent 하다고 한다.
- initial read: 만약 S의 트랜잭션 T₁이 Q의 초기값을 read 했다면, S'에서도 T₁은 Q의 초기값을 read 해야 한다.
- same read: 만약 S의 T₁이 T₂로부터 생성된 Q를 read 했다면, S'에서도 T₁은 T₂로부터 생성된 Q값을 읽어야 한다.
- final write: 만약 S의 T₁이 final write(Q)를 했다면 S'에서도 T₁이 final write(Q)를 해야 한다.
그중 특히 S가 serial schedule과 view equivalent 하면 S는 뷰 직렬 가능한 스케줄이다.
모든 충돌 직렬 가능한 스케줄은 뷰 직렬 가능하다. 즉, 충돌 직렬은 뷰 직렬의 부분 집합이다. 위 예제는 뷰 직렬 가능하지만, 충돌 직렬 가능하지 않은 예제이다. 위와 같은 케이스의 특징으로는 T₂₈처럼 blind write를 가지고 있다.
복구 가능한 스케줄(Recoverable Schedule)
스케줄은 serializable 해야 하고, 복구 가능해야 한다. 만약에 T₂가 T₁에 의해 변경된 데이터를 사용할 때, T₁이 commit 되기 전에 T₂는 commit 하면 안 된다. 그래야 T₁이 abort 될 때, T₂도 abort 될 수 있다.
위 케이스는 복구 가능하지 않은 스케줄이다. 복구하기 위해서 T₈의 commit이 먼저 일어나야 한다. 하지만 위의 경우는 T₉이 A를 read 한 이후에 commit 했다. 이 상황에서는 T₈이 abort 되면 T₉는 abort 될 수 없기 때문에 데이터베이스가 inconsistent 해진다. 복구 가능 스케줄은 단순히 T₉의 commit보다 T₈의 commit을 먼저 하는 것으로 성립된다.
캐스케이드 스케줄(Cascade Schedule)
T₁₀ 트랜잭션이 실패하면 T₁₁, T₁₂ 모두 롤백돼야 한다. 이것을 cascading rollback이라 한다. 이러한 특징을 가진 스케줄을 캐스케이드 스케줄이라 하는데, 캐스케이드 스케줄은 복구 가능하지 않은 스케줄을 만든다. Cascadeless 스케줄은 다른 트랜잭션이 읽기 전에 commit을 해야 한다. 결국 Cascadeless 스케줄은 모두 복구 가능한 스케줄이다.
'CS > 데이터베이스' 카테고리의 다른 글
| InnoDB 인덱스 개념과 데이터 읽기 방식 + 실습 (0) | 2023.01.28 |
|---|---|
| 데이터베이스 관리 시스템의 아키텍처(DBMS Architecture) (2) | 2022.10.15 |
| 트랜잭션의 병행 수행(concurrency)와 병행 제어(concurrency control) (0) | 2022.10.09 |
| 데이터베이스 장애(failure)와 회복(recovery) (0) | 2022.10.02 |
| 트랜잭션(Transaction) 개념과 트랜잭션의 특성(ACID) (0) | 2022.09.30 |