
일반적인 데이터베이스 개론에서 트랜잭션 개념 다음 내용이므로 순서대로 공부하는 것을 선호하신다면 데이터베이스 트랜잭션 개념까지 학습하시면 도움이 될 수 있습니다. 잘못된 부분이 있다면 피드백 부탁드립니다.
들어가기 앞서

트랜잭션의 ACID를 보장하고, 데이터베이스를 모순이 없는 일관된 상태로 유지하기 위해서 DBMS는 회복 기능을 제공한다. 회복이란 장애가 발생했을 때, 데이터베이스를 장애 발생하기 전 일관된 상태로 복구하는 것이다.
장애(failure)의 유형
시스템이 제대로 동작하지 않은 상태를 장애(failure)라고 한다. 가볍게 표만 보고 넘어가 보자.
| 유형 | 설명 | |
| 트랜잭션 장애 | 의미 | 트랜잭션 수행 중 오류가 발생하여 정상적으로 수행을 계속 할 수 없는 상태 |
| 원인 | 트랜잭션의 논리적 오류. 잘못된 데이터 입력, 시스템 자원의 과다 사용 요구, 처리 대상 데이터 부재 | |
| 시스템 장애 | 의미 | 하드웨어의 결함으로 정상적으로 수행을 계속할 수 없는 상태 |
| 원인 | 하드웨어 이상으로 메인 메모리에 저장된 정보가 손실되거나 교착 상태가 발생한 경우 | |
| 미디어 장애 | 의미 | 디스크 장치의 결함으로 디스크에 저장된 데이터베이스의 일부 혹은 전체가 손상된 상태 |
| 원인 | 디스크 헤드의 손상, 고장 등 | |
데이터베이스의 저장 연산
일반적으로 디스크와 메인 메모리 간의 데이터 이동은 블록(block) 단위로 수행한다.
1) 디스크에 있는 블록 = 디스크 블록 2) 메인 메모리에 있는 블록 = 메모리 버퍼 블록
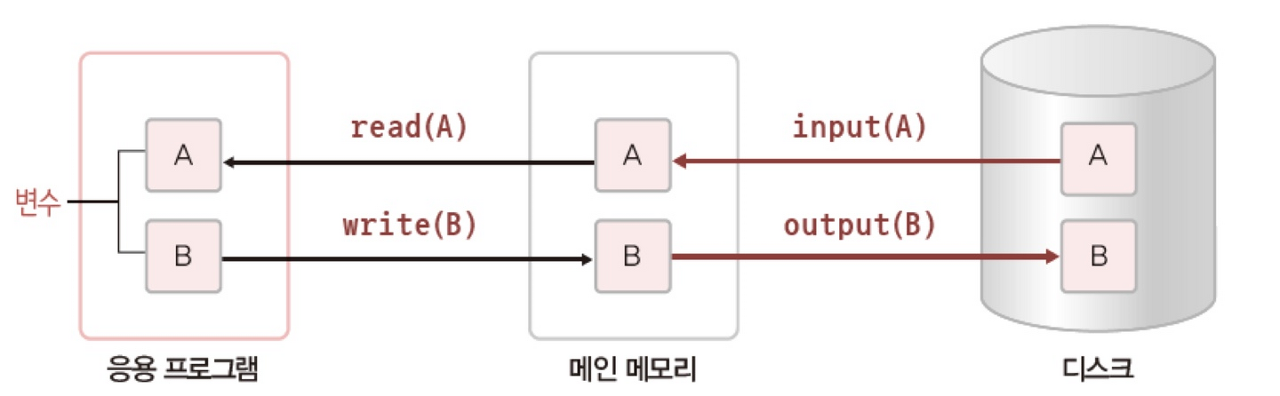
- input(X) : 디스크 블록에 저장된 데이터 X를 메인 메모리 버퍼 블록으로 이동시키는 연산
- output(X): 메인 메모리 버퍼 블록에 있는 데이터 X를 디스크 블록으로 이동시키는 연산
- read(X): 메인 메모리 버퍼 블록에 저장되어 있는 데이터 X를 프로그램 변수로 읽어오는 연산
- write(X) 프로그램의 변수 값을 메인 메모리 버퍼 블록에 있는 데이터 X에 기록하는 연산
회복의 개념과 배경 지식
회복은 장애가 발생했을 때, 데이터베이스를 장애가 발생하기 전 모순이 없고 일관된 상태로 복구시키는 것이다. Recovery는 트랜잭션 특성 중 Atomicity, Durability와 관계가 있다. DBMS의 회복 관리자(recovery manager)는 장애 발생을 탐지하고 데이터베이스를 복구하는 기능을 담당한다. 일반적으로 복구 중에는 데이터베이스에 접근해 업무 처리를 할 수 없으므로 빠른 시간 내에 이루어져야 한다.
transaction management module 중 recovery control module이 있는데, 이것이 DBMS의 회복 관리자인지 헷갈린다. 내 생각에는 표준에 관한 이야기기 때문에 용어보단 기능이 중요하다 생각한다. 나중에 진짜 구현체의 회복 관리 구성을 봐야 제대로 이해할 수 있을 것 같다.
회복을 위해 복사본을 만드는 방법
데이터베이스 회복의 핵심 원리는 데이터 중복이다. 복사본을 이용해 원래의 상태로 복원한다.
- 덤프(dump): 데이터베이스 전체를 다른 저장 장치에 주기적으로 복사하는 방법
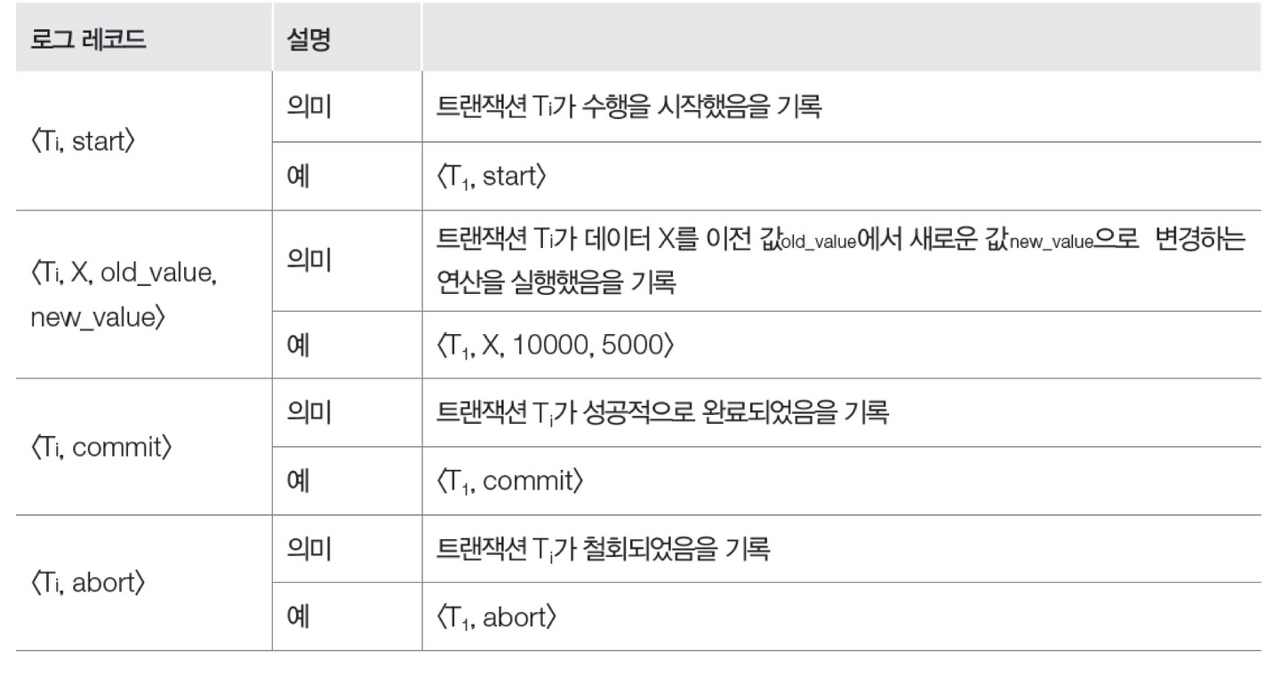
- 로그(log): 데이터베이스에서 변경 연산이 실행될 때마다 데이터를 변경하기 이전 값과 변경한 이후의 값을 별도의 파일에 기록하는 방법.
회복을 위한 연산
회복을 위해 저장된 복사본(덤프나 로그)을 이용해 회복하는 기본적인 연산은 redo와 undo가 있다.
- 재실행(redo): 가장 최근에 저장한 데이터베이스 복사본을 가져와 로그를 이용해 복사본이 만들어진 이후에 실행된 모든 변경 연산을 재실행하여 장애가 발생하기 직전의 데이터베이스 상태로 복구한다.
- 취소(undo): 로그를 이용해 지금까지 실행된 모든 변경 연산을 취소해, 데이터베이스를 원래의 상태로 복구한다.
전반적으로 손상된 경우 redo를, 변경 중이었거나 이미 변경된 내용만 신뢰성을 잃은 경우에 undo를 주로 사용한다. redo 연산과, undo 연산을 실행하는 데 로그가 중요하게 사용된다.
로그 레코드 종류
로그는 데이터베이스의 변경 연산에 대해 데이터를 변경하기 이전의 값, 변경한 이후의 값을 기록한 것이다. 이러한 로그를 저장한 로그파일은 로그 레코드 단위로 기록된다. 데이터베이스에 대한 변경 연산은 트랜잭션 단위로 실행되므로 로그 레코드도 트랜잭션의 수행과 함께 기록된다.
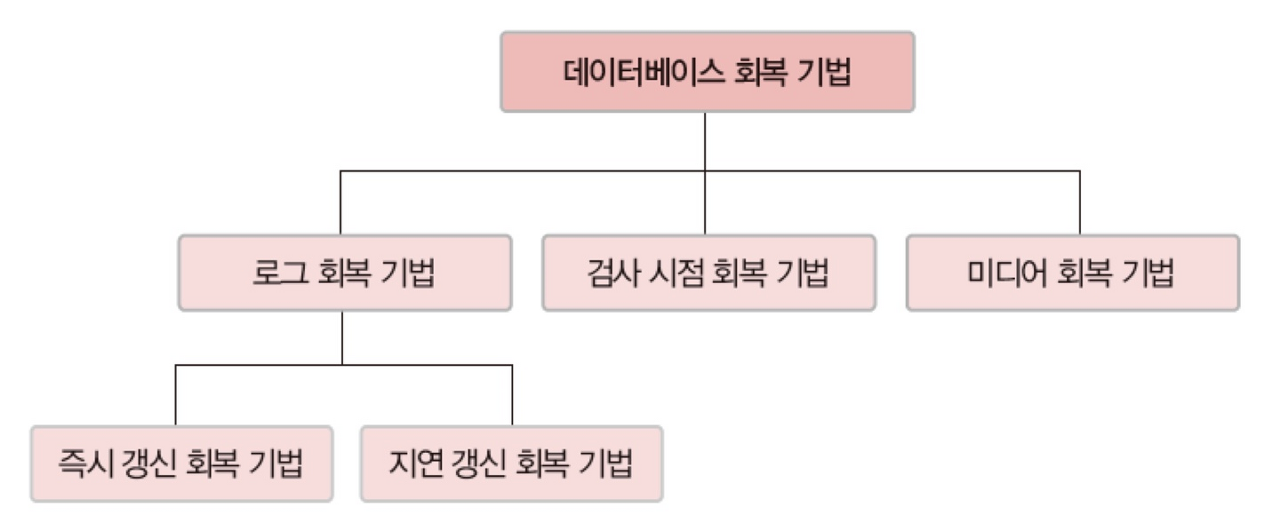
회복 기법의 분류
장애가 발생하는 시점과 유형이 다양하고, 데이터베이스를 빠른 시간 내에 복구해야 하므로 실제로 DBMS는 좀 더 복잡하고 효율적인 회복 기법들을 사용한다.
로그 회복 기법
로그를 이용한 회복 기법은 데이터를 변경한 연산 결과를 데이터베이스에 반영하는 시점에 따라 즉시 갱신 회복과 지연 갱신 회복으로 나뉜다. 일반적으로 가장 많이 사용된다.
즉시 갱신 회복 기법(immediate update)
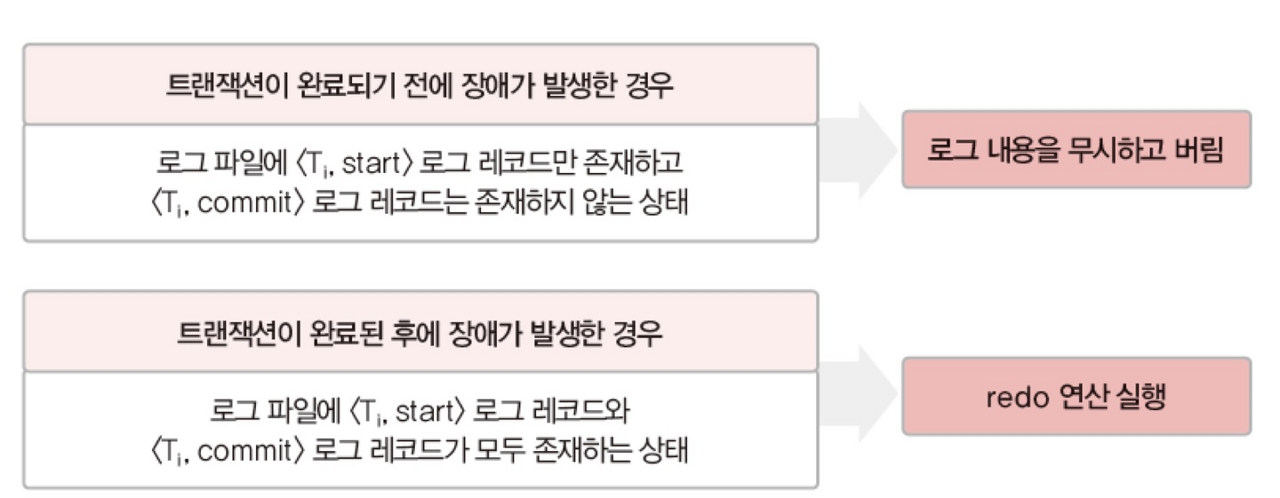
트랜잭션 수행 중에 데이터를 변경한 연산의 결과를 데이터베이스에 즉시 반영한다. 그리고 장애 발생에 대비하기 위해 변경에 대한 내용을 로그파일에 기록한다. 회복할 때, 로그를 정상적으로 사용하려면 트랜잭션에서 데이터 변경 연산이 실행됐을 때, 로그 파일에 로그 레코드를 먼저 기록하고, 변경 연산을 반영해야 한다. 장애 발생 시점에 따라 redo, undo를 결정하여 데이터베이스를 복구한다. 결정하는 기준은 아래와 같다.
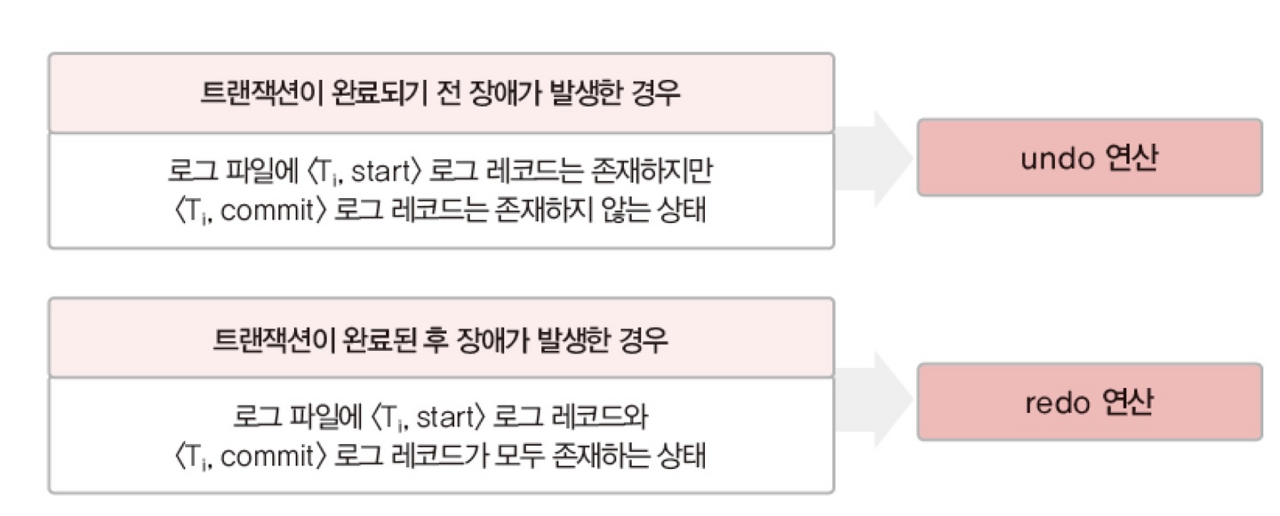
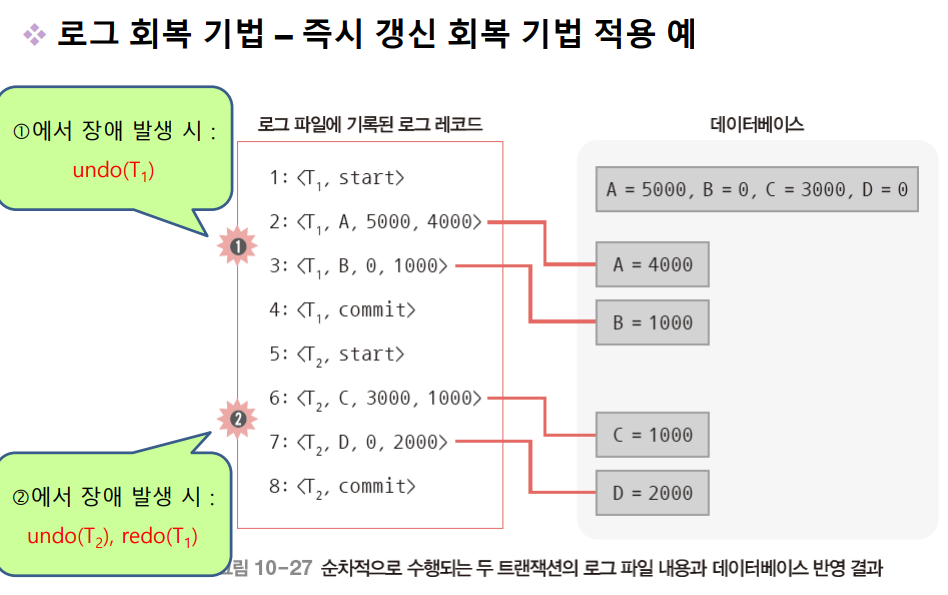
1번 시점에서 T₁ 트랜잭션의 수행이 아직 완료되기 전이므로 로그 파일에 <T₁, start> 로그 레코드만 존재하고 <T₁, commit>이 존재하지 않는다. 따라서 undo(T₁) 연산을 수행해야 한다. 즉, 로그 내용을 이용해 지금까지 변경한 데이터의 값을 변경 연산 이전의 값으로 되돌려야 한다. T₁, 트랜잭션에 undo 연산을 수행하면 A의 잔액은 5000으로 변경된다. 만약 되돌려야 하는 데이터가 여러 개인 경우 역순으로 undo 연산을 수행한다.
2번 시점에는 T₁, 트랜잭션의 수행이 이미 완료되었음을 알 수 있다. 반면 T₂는 commit이 수행되기 전이다. 즉, T₁에 대해서 redo 연산을 T₂에 대해서 undo 연산을 수행해야 한다. 중요한 것은 undo와 redo가 같이 수행될 때, undo 먼저 실행한다. redo 연산이 필요한 데이터가 여러 개인 경우에는 로그에 기록된 순서대로 redo 연산을 수행한다.
데이터를 되돌릴 때, undo는 역순으로 복구하고, redo는 정순으로 복구한다. undo와 redo가 동시에 있는 경우 undo가 먼저 실행되는 것을 잊지 말자.
지연 갱신 회복 기법(deferred update)
지연 갱신 회복 기법은 트랜잭션이 수행되는 도중 데이터 변경 연산의 결과를 데이터베이스에 즉시 반영하지 않고 로그 파일에만 기록해뒀다가, 트랜잭션이 부분 완료된 후에 로그에 기록된 내용을 이용해 데이터베이스에 한 번에 반영한다. 즉, undo 연산이 필요가 없다. 따라서 redo 연산만 필요하므로 로그 레코드에 이전 값을 기록할 필요가 없다. 그러므로 변경 연산 실행에 대한 로그 레코드는 <Ti, X, new_value> 형식으로 기록된다.
undo는 역순으로 old_value로 갱신하기 때문에 old_value를 저장해야 하지만, redo는 정순으로 new_value로 갱신하기 때문에 new_value가 필요하다. 따라서 지연 갱신 회복은 redo만 있기 때문에, new_value만 있으면 된다.
지연 갱신 회복 기법은 아래 기준에 따라서 회복 전략이 나뉜다.
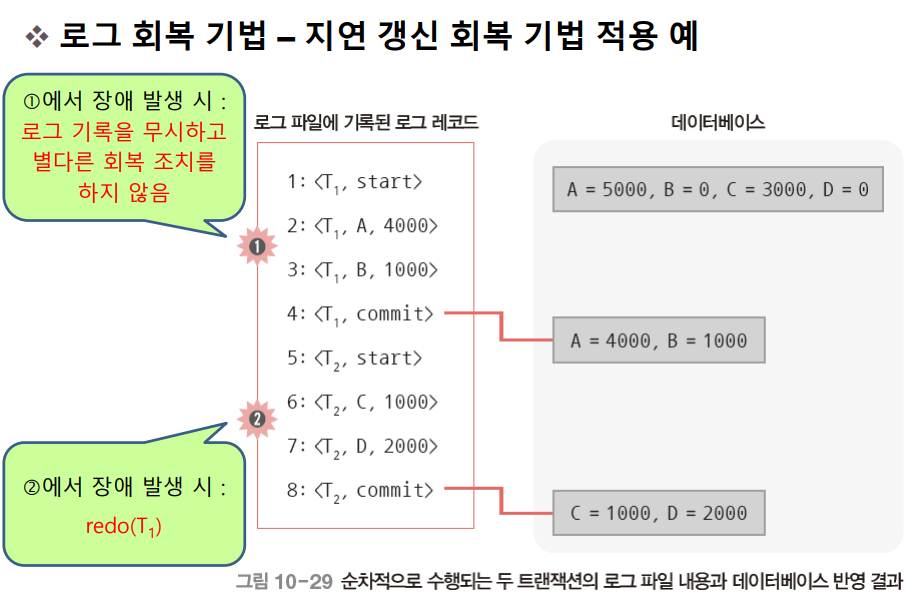
1번 시점에서는 T₁ 트랜잭션의 수행이 아직 완료되기 전이므로 로그 파일에 <T₁, start> 로그만 존재하고 commit 로그 레코드는 없다. 지연 갱신 회복 기법에서는 데이터베이스에 바로 반영되지 않기 때문에 로그파일을 그냥 버리면 된다. 회복 조치 없이 그냥 트랜잭션의 수행을 다시 시작하기만 하면 된다.
2번 시점에서는 T₁ 트랜잭션만 이미 완료되었다. 따라서 redo(T₁) 연산을 수행하여 A의 값이 4000, B의 값이 1000이 되도록 한다.
검사 시점 회복 기법
로그를 이용해 회복하기 위해서는 로그 전체를 분석해서 로그에 기록된 모든 트랜잭션을 대상으로 redo나 undo를 결정해야 한다. 하지만 로그 전체를 대상으로 회복 기법을 적용하면 데이터베이스 회복에 많은 시간이 소요된다. 또한 redo가 필요 없는 트랜잭션에도 redo 연산을 수행하는 일이 발생하기도 한다. 이러한 비효율성의 문제를 해결하기 위해 검사 시점 회복 기법이 제안됐다.
- 로그 기록을 이용하되, 일정 시간 간격으로 검사 시점(checkpoint)을 만들어 둔다.
- 장애 발생 시, 가장 최근 checkpoint 이전의 트랜잭션에는 회복 작업을 수행하지 않는다.
- 장애 발생 시, 가장 최근 checkpoint 이후의 트랜잭션만 회복 작업을 수행한다.
검사 시점 회복 기법을 사용하면, 회복의 작업 범위가 검사 시점으로 정해 지므로 불필요한 회복 작업을 줄여 회복 시간을 단축할 수 있다. 일정 시간 간격으로 검사 시점이 되면, 메인 메모리에 있는 모든 로그 레코드를 안정 저장 장치에 있는 로그 파일에 기록하고, 변경 내용을 데이터베이스에 반영한다. 그다음 검사 시점을 표시하는 <checkpoint L> 형식의 로그 레코드를 로그 파일에 기록한다.
L은 현재 실행되고 있는 트랜잭션 리스트이다.
장애가 발생된 경우, 로그 파일에서 가장 최근의 checkpoint 로그 레코드를 찾아서 그 이후의 로그 기록에만 회복 작업을 수행한다. 즉, checkpoint 로그 레코드를 이용해 회복 작업의 범위를 지정한다. 범위가 지정되면, 즉시 갱신이나 지연 갱신을 이용해 회복 작업을 수행한다.
미디어 회복 기법
디스크에 발생할 수 있는 장애에 대비한 회복 기법이다. 미디어 회복 기법은 전체 데이터베이스 내용을 일정 주기마다 다른 안전한 저장 장치에 복사해두는 덤프를 이용한다. 디스크에 장애가 발생하면, 가장 최근에 복사해둔 덤프를 이용해 장애 발생 이전의 데이터베이스 상태로 복구한다. 그런 다음 필요에 따라 로그의 내용을 토대로 redo 연산을 수행한다. 전체 데이터베이스를 다른 저장 장치에 복사하는 것은 비용이 많이 들고, 복사하는 동안에 트랜잭션 수행을 중단해야 하므로 미디어 회복 기법은 CPU가 낭비되는 단점이 있다.
'CS > 데이터베이스' 카테고리의 다른 글
| InnoDB 인덱스 개념과 데이터 읽기 방식 + 실습 (0) | 2023.01.28 |
|---|---|
| 데이터베이스 관리 시스템의 아키텍처(DBMS Architecture) (2) | 2022.10.15 |
| 트랜잭션의 병행 수행(concurrency)와 병행 제어(concurrency control) (0) | 2022.10.09 |
| 견고하게 트랜잭션 스케줄(Transaction Schedules) 개념 잡기 (0) | 2022.10.01 |
| 트랜잭션(Transaction) 개념과 트랜잭션의 특성(ACID) (0) | 2022.09.30 |
일반적인 데이터베이스 개론에서 트랜잭션 개념 다음 내용이므로 순서대로 공부하는 것을 선호하신다면 데이터베이스 트랜잭션 개념까지 학습하시면 도움이 될 수 있습니다. 잘못된 부분이 있다면 피드백 부탁드립니다.
들어가기 앞서
트랜잭션의 ACID를 보장하고, 데이터베이스를 모순이 없는 일관된 상태로 유지하기 위해서 DBMS는 회복 기능을 제공한다. 회복이란 장애가 발생했을 때, 데이터베이스를 장애 발생하기 전 일관된 상태로 복구하는 것이다.
장애(failure)의 유형
시스템이 제대로 동작하지 않은 상태를 장애(failure)라고 한다. 가볍게 표만 보고 넘어가 보자.
| 유형 | 설명 | |
| 트랜잭션 장애 | 의미 | 트랜잭션 수행 중 오류가 발생하여 정상적으로 수행을 계속 할 수 없는 상태 |
| 원인 | 트랜잭션의 논리적 오류. 잘못된 데이터 입력, 시스템 자원의 과다 사용 요구, 처리 대상 데이터 부재 | |
| 시스템 장애 | 의미 | 하드웨어의 결함으로 정상적으로 수행을 계속할 수 없는 상태 |
| 원인 | 하드웨어 이상으로 메인 메모리에 저장된 정보가 손실되거나 교착 상태가 발생한 경우 | |
| 미디어 장애 | 의미 | 디스크 장치의 결함으로 디스크에 저장된 데이터베이스의 일부 혹은 전체가 손상된 상태 |
| 원인 | 디스크 헤드의 손상, 고장 등 | |
데이터베이스의 저장 연산
일반적으로 디스크와 메인 메모리 간의 데이터 이동은 블록(block) 단위로 수행한다.
1) 디스크에 있는 블록 = 디스크 블록 2) 메인 메모리에 있는 블록 = 메모리 버퍼 블록
- input(X) : 디스크 블록에 저장된 데이터 X를 메인 메모리 버퍼 블록으로 이동시키는 연산
- output(X): 메인 메모리 버퍼 블록에 있는 데이터 X를 디스크 블록으로 이동시키는 연산
- read(X): 메인 메모리 버퍼 블록에 저장되어 있는 데이터 X를 프로그램 변수로 읽어오는 연산
- write(X) 프로그램의 변수 값을 메인 메모리 버퍼 블록에 있는 데이터 X에 기록하는 연산
회복의 개념과 배경 지식
회복은 장애가 발생했을 때, 데이터베이스를 장애가 발생하기 전 모순이 없고 일관된 상태로 복구시키는 것이다. Recovery는 트랜잭션 특성 중 Atomicity, Durability와 관계가 있다. DBMS의 회복 관리자(recovery manager)는 장애 발생을 탐지하고 데이터베이스를 복구하는 기능을 담당한다. 일반적으로 복구 중에는 데이터베이스에 접근해 업무 처리를 할 수 없으므로 빠른 시간 내에 이루어져야 한다.
transaction management module 중 recovery control module이 있는데, 이것이 DBMS의 회복 관리자인지 헷갈린다. 내 생각에는 표준에 관한 이야기기 때문에 용어보단 기능이 중요하다 생각한다. 나중에 진짜 구현체의 회복 관리 구성을 봐야 제대로 이해할 수 있을 것 같다.
회복을 위해 복사본을 만드는 방법
데이터베이스 회복의 핵심 원리는 데이터 중복이다. 복사본을 이용해 원래의 상태로 복원한다.
- 덤프(dump): 데이터베이스 전체를 다른 저장 장치에 주기적으로 복사하는 방법
- 로그(log): 데이터베이스에서 변경 연산이 실행될 때마다 데이터를 변경하기 이전 값과 변경한 이후의 값을 별도의 파일에 기록하는 방법.
회복을 위한 연산
회복을 위해 저장된 복사본(덤프나 로그)을 이용해 회복하는 기본적인 연산은 redo와 undo가 있다.
- 재실행(redo): 가장 최근에 저장한 데이터베이스 복사본을 가져와 로그를 이용해 복사본이 만들어진 이후에 실행된 모든 변경 연산을 재실행하여 장애가 발생하기 직전의 데이터베이스 상태로 복구한다.
- 취소(undo): 로그를 이용해 지금까지 실행된 모든 변경 연산을 취소해, 데이터베이스를 원래의 상태로 복구한다.
전반적으로 손상된 경우 redo를, 변경 중이었거나 이미 변경된 내용만 신뢰성을 잃은 경우에 undo를 주로 사용한다. redo 연산과, undo 연산을 실행하는 데 로그가 중요하게 사용된다.
로그 레코드 종류
로그는 데이터베이스의 변경 연산에 대해 데이터를 변경하기 이전의 값, 변경한 이후의 값을 기록한 것이다. 이러한 로그를 저장한 로그파일은 로그 레코드 단위로 기록된다. 데이터베이스에 대한 변경 연산은 트랜잭션 단위로 실행되므로 로그 레코드도 트랜잭션의 수행과 함께 기록된다.
회복 기법의 분류
장애가 발생하는 시점과 유형이 다양하고, 데이터베이스를 빠른 시간 내에 복구해야 하므로 실제로 DBMS는 좀 더 복잡하고 효율적인 회복 기법들을 사용한다.
로그 회복 기법
로그를 이용한 회복 기법은 데이터를 변경한 연산 결과를 데이터베이스에 반영하는 시점에 따라 즉시 갱신 회복과 지연 갱신 회복으로 나뉜다. 일반적으로 가장 많이 사용된다.
즉시 갱신 회복 기법(immediate update)
트랜잭션 수행 중에 데이터를 변경한 연산의 결과를 데이터베이스에 즉시 반영한다. 그리고 장애 발생에 대비하기 위해 변경에 대한 내용을 로그파일에 기록한다. 회복할 때, 로그를 정상적으로 사용하려면 트랜잭션에서 데이터 변경 연산이 실행됐을 때, 로그 파일에 로그 레코드를 먼저 기록하고, 변경 연산을 반영해야 한다. 장애 발생 시점에 따라 redo, undo를 결정하여 데이터베이스를 복구한다. 결정하는 기준은 아래와 같다.
1번 시점에서 T₁ 트랜잭션의 수행이 아직 완료되기 전이므로 로그 파일에 <T₁, start> 로그 레코드만 존재하고 <T₁, commit>이 존재하지 않는다. 따라서 undo(T₁) 연산을 수행해야 한다. 즉, 로그 내용을 이용해 지금까지 변경한 데이터의 값을 변경 연산 이전의 값으로 되돌려야 한다. T₁, 트랜잭션에 undo 연산을 수행하면 A의 잔액은 5000으로 변경된다. 만약 되돌려야 하는 데이터가 여러 개인 경우 역순으로 undo 연산을 수행한다.
2번 시점에는 T₁, 트랜잭션의 수행이 이미 완료되었음을 알 수 있다. 반면 T₂는 commit이 수행되기 전이다. 즉, T₁에 대해서 redo 연산을 T₂에 대해서 undo 연산을 수행해야 한다. 중요한 것은 undo와 redo가 같이 수행될 때, undo 먼저 실행한다. redo 연산이 필요한 데이터가 여러 개인 경우에는 로그에 기록된 순서대로 redo 연산을 수행한다.
데이터를 되돌릴 때, undo는 역순으로 복구하고, redo는 정순으로 복구한다. undo와 redo가 동시에 있는 경우 undo가 먼저 실행되는 것을 잊지 말자.
지연 갱신 회복 기법(deferred update)
지연 갱신 회복 기법은 트랜잭션이 수행되는 도중 데이터 변경 연산의 결과를 데이터베이스에 즉시 반영하지 않고 로그 파일에만 기록해뒀다가, 트랜잭션이 부분 완료된 후에 로그에 기록된 내용을 이용해 데이터베이스에 한 번에 반영한다. 즉, undo 연산이 필요가 없다. 따라서 redo 연산만 필요하므로 로그 레코드에 이전 값을 기록할 필요가 없다. 그러므로 변경 연산 실행에 대한 로그 레코드는 <Ti, X, new_value> 형식으로 기록된다.
undo는 역순으로 old_value로 갱신하기 때문에 old_value를 저장해야 하지만, redo는 정순으로 new_value로 갱신하기 때문에 new_value가 필요하다. 따라서 지연 갱신 회복은 redo만 있기 때문에, new_value만 있으면 된다.
지연 갱신 회복 기법은 아래 기준에 따라서 회복 전략이 나뉜다.
1번 시점에서는 T₁ 트랜잭션의 수행이 아직 완료되기 전이므로 로그 파일에 <T₁, start> 로그만 존재하고 commit 로그 레코드는 없다. 지연 갱신 회복 기법에서는 데이터베이스에 바로 반영되지 않기 때문에 로그파일을 그냥 버리면 된다. 회복 조치 없이 그냥 트랜잭션의 수행을 다시 시작하기만 하면 된다.
2번 시점에서는 T₁ 트랜잭션만 이미 완료되었다. 따라서 redo(T₁) 연산을 수행하여 A의 값이 4000, B의 값이 1000이 되도록 한다.
검사 시점 회복 기법
로그를 이용해 회복하기 위해서는 로그 전체를 분석해서 로그에 기록된 모든 트랜잭션을 대상으로 redo나 undo를 결정해야 한다. 하지만 로그 전체를 대상으로 회복 기법을 적용하면 데이터베이스 회복에 많은 시간이 소요된다. 또한 redo가 필요 없는 트랜잭션에도 redo 연산을 수행하는 일이 발생하기도 한다. 이러한 비효율성의 문제를 해결하기 위해 검사 시점 회복 기법이 제안됐다.
- 로그 기록을 이용하되, 일정 시간 간격으로 검사 시점(checkpoint)을 만들어 둔다.
- 장애 발생 시, 가장 최근 checkpoint 이전의 트랜잭션에는 회복 작업을 수행하지 않는다.
- 장애 발생 시, 가장 최근 checkpoint 이후의 트랜잭션만 회복 작업을 수행한다.
검사 시점 회복 기법을 사용하면, 회복의 작업 범위가 검사 시점으로 정해 지므로 불필요한 회복 작업을 줄여 회복 시간을 단축할 수 있다. 일정 시간 간격으로 검사 시점이 되면, 메인 메모리에 있는 모든 로그 레코드를 안정 저장 장치에 있는 로그 파일에 기록하고, 변경 내용을 데이터베이스에 반영한다. 그다음 검사 시점을 표시하는 <checkpoint L> 형식의 로그 레코드를 로그 파일에 기록한다.
L은 현재 실행되고 있는 트랜잭션 리스트이다.
장애가 발생된 경우, 로그 파일에서 가장 최근의 checkpoint 로그 레코드를 찾아서 그 이후의 로그 기록에만 회복 작업을 수행한다. 즉, checkpoint 로그 레코드를 이용해 회복 작업의 범위를 지정한다. 범위가 지정되면, 즉시 갱신이나 지연 갱신을 이용해 회복 작업을 수행한다.
미디어 회복 기법
디스크에 발생할 수 있는 장애에 대비한 회복 기법이다. 미디어 회복 기법은 전체 데이터베이스 내용을 일정 주기마다 다른 안전한 저장 장치에 복사해두는 덤프를 이용한다. 디스크에 장애가 발생하면, 가장 최근에 복사해둔 덤프를 이용해 장애 발생 이전의 데이터베이스 상태로 복구한다. 그런 다음 필요에 따라 로그의 내용을 토대로 redo 연산을 수행한다. 전체 데이터베이스를 다른 저장 장치에 복사하는 것은 비용이 많이 들고, 복사하는 동안에 트랜잭션 수행을 중단해야 하므로 미디어 회복 기법은 CPU가 낭비되는 단점이 있다.
'CS > 데이터베이스' 카테고리의 다른 글
| InnoDB 인덱스 개념과 데이터 읽기 방식 + 실습 (0) | 2023.01.28 |
|---|---|
| 데이터베이스 관리 시스템의 아키텍처(DBMS Architecture) (2) | 2022.10.15 |
| 트랜잭션의 병행 수행(concurrency)와 병행 제어(concurrency control) (0) | 2022.10.09 |
| 견고하게 트랜잭션 스케줄(Transaction Schedules) 개념 잡기 (0) | 2022.10.01 |
| 트랜잭션(Transaction) 개념과 트랜잭션의 특성(ACID) (0) | 2022.09.30 |